
1. 判断回文
- 字符串转置,然后逐位比较;
- 字符串转置,直接 equals 比较;
- for 循环 length/2 次,首位和末尾逐次比较;
2. jvm,讲讲gc
jvm 将内存划分为:方法区、堆区、虚拟机栈、本地方法栈、程序计数器。
方法区:
- 要加载的类的信息、静态变量、构造函数、final 定义的信息,包含运行时常量池。
- 全局共享。
- 对应持久带,会被 GC,但很少发生。
堆区:
- 所有线程共享,主要存放对象实例和数组。
虚拟机栈:
- 每个方法被执行时,产生一个栈帧,用来存储局部变量表、动态链接、操作数和方法出口等信息。
本地方法栈:
- 执行 native 方法。
程序计数器:
- 存储当前线程执行的字节码行号。
GC:对方法区和堆区进行垃圾回收,回收的对象多是那些不存在任何引用的对象。
GC 算法:标记-清除算法、复制算法、标记-整理算法、分代收集算法。
GC 收集器:串行收集器、ParNew GC、Parallel Scavenge GC、CMS 收集器、G1 收集器、Serial Old 收集器、Parallel Old 收集器、RTSJ 垃圾收集器。
3. 讲讲 osi 七层模型
- 应用层:文件传输、管理,邮件处理。协议:HTTP、FTP等。
- 表示层:编码转换、数据解析、管理数据的加解密。协议:Telnet、SNMP、Gopher等。
- 会话层:通信连接的建立、保持会话过程通信连接的畅通。协议:DNS、SMTP等。
- 传输层:定义一些传输数据的协议和端口。协议:TCP、UDP等。
- 网络层:控制子网的运行,如逻辑编址,分组传输,路由选择。协议:IP、ICMP、ARP等。
- 数据链路层:对物理层传输的比特流包装,物理寻址等。协议:PPP、SDLC、帧中继等。
- 物理层:定义物理设备的标准。协议:IEEE 802.1A、IEEE802.2等。

推荐阅读:OSI七层协议大白话解读
OSI七层协议模型、TCP/IP四层模型
4. tcp udp
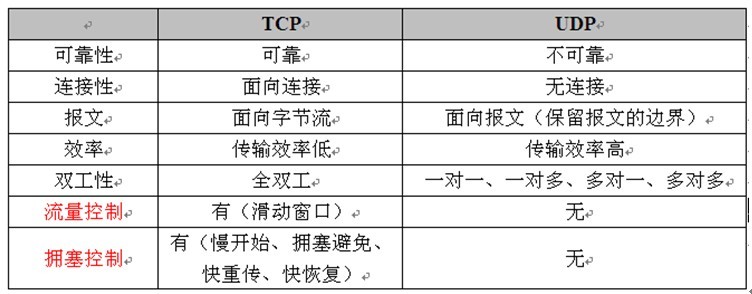
区别:
- TCP 是面向连接的、UDP 是面向无连接的;
- UDP 程序结构简单;
- TCP 是面向字节流的,UDP 是基于数据报的;
- UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给 UDP 多长的报文,UDP 就照样发送,即一次发送一个报文。(理解:不拆分,所以有原生的边界)。
- TCP 有一个缓冲,当应用程序传送的数据块太长,TCP 就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP 也可以等待积累有足够多的字节后再构成报文段发送出去。(理解:要拆分,所以没有边界,直接拼接上)。
- TCP 保证数据正确性、UDP 可能丢包;
- TCP 保证数据顺序,UDP 不保证。
- TCP 有流量控制(滑动窗口)、拥塞控制(拥塞窗口)机制。
具体编程时,
socket()的参数不同:
- UDP Server 不需要调用 listen 和 accept;
- UDP 收发数据用 sendto/recvfrom 函数;
- TCP:地址信息在 connect/accept 时确定;
- UDP:在 sendto/recvfrom 函数中每次均需指定地址信息;
- UDP:shutdown 函数无效。
5. 设计模式 懒汉饿汉区别,抽象简单工厂区别
饿汉和懒汉式设计模式中单例模式的两大种方式:
饿汉式,在类创建的同时已经创建好了一个静态对象供使用,是线程安全的,但对内存有一定消耗。
懒汉式,延时加载,线程不安全,为了实现线程安全有几种写法:
- 加方法锁(有漏洞)
- 双锁(有漏洞)
- 双锁 + valatile等。(无漏洞、繁琐)
- 静态内部类(也叫做 Holder 方法无漏洞)【常用】。
- 枚举(无漏洞、简单)【常用】。有关枚举方式推荐阅读:为什么我墙裂建议大家使用枚举来实现单例。枚举的分析如下:
- 枚举类被加载时,会使用
ClassLoader的loadClass方法(此方法使用同步代码块保证线程安全)。 - 枚举的序列化和反序列化是特殊定制的,可避免因反射引起的代码重排问题。
- 枚举单例的实例代码如下:
- 枚举类被加载时,会使用
1 | public enum Singleton{ |
+ 枚举单例,再增加懒加载功能(配合静态内部类实现)如下:
1 | public class Singleton{ |
简单工厂:拥有一个工厂方法,接受一个参数,通过不同的参数实例化不同的产品类。
优点:简单、代码量少。
缺点:
- 此工厂方法负责生产任何“东西”,负担太重;
- 在遵循开闭原则下,简单工厂无法增加新的产品。
工厂方法:针对每一种产品提供一个工厂类,通过不同的工厂实例来创建不同的产品实例。
优点:可解决简单工厂的缺点,当需要增加某类“东西”时,不需要修改原工厂,只需要添加生产这类“东西”的工厂即可。
缺点:对于某些可以生成产品族的情况处理较复杂。比如可以将奔驰所有车看做一个产品族。
抽象工厂:用于应对产品族概念的,与工厂方法类似,将工厂方法中的共同点抽象出来。
优点:便于增加产品族。
另一种总结:
- 简单工厂:定义了一个类来负责创建其他产品类的实例。
- 工厂方法:工厂父类负责定义创建产品对象的公共接口,而工厂子类则决定生成具体的产品对象,这样类实例的创建就可以在子类中单独完成了。
- 抽象工厂:提供一个创建一系列相关或互相依赖对象的接口,而无须指定它们具体的类。
推荐阅读:简单工厂、工厂方法、抽象工厂、策略模式、策略与工厂的区别
6. linux 删除日志文件最后十行
1 | A=$(sed -n '$=' a.txt) // 输出a.txt的行数赋给 A,取值时用$ |
注:如果将 10 改成 50,就成了删除最后 50 行了。a.txt 可以修改为题目中的日志文件。
推荐阅读:Linux sed命令
shell中sed命令的用法
7. sql 注入
SQL 注入:SQL注入是比较常见的网络攻击方式之一,它不是利用操作系统的BUG来实现攻击,而是针对程序员编程时的疏忽,通过SQL语句,实现无帐号登录,甚至篡改数据库。
注入思路:
- 寻找到SQL注入的位置
- 判断服务器类型和后台数据库类型
- 针对不同的服务器和数据库特点进行SQL注入攻击
应对办法:
- 采用预编译语句集 PreparedStatement;
- 使用正则表达式过滤;
- 字符串过滤;
- jsp 中进行函数检查;
8. 快排时间复杂度,空间复杂度
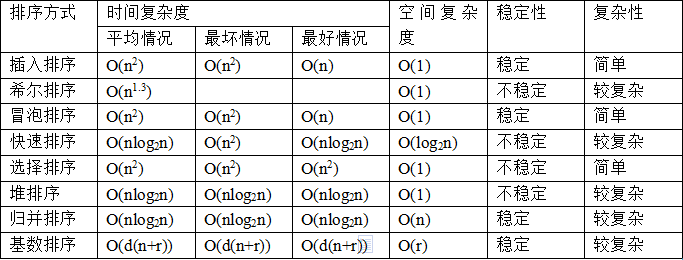
快排时间复杂度的三种证明办法:为什么快速排序的时间复杂度是 O(nlogn)
Tips:
- 快速排序排的是一个左右闭合区间;
- 快排每一趟只将一个数排好,放在正确的位置;
- key 能选最左边也能选最右边,也可以随机选
- 当一组数为有序时使用快排对这组数排序,此时为快排的最坏情况;时间复杂度最高,为 O(N^2);
顺口溜:
- 不稳定:快些(希)选一堆小伙伴。
- 时间复杂度O(NlogN):快归队(堆)。
9. 数据库隔离级别
数据库事务的隔离级别有 4 种,由低到高分别为Read uncommitted 、Read committed 、Repeatable read 、Serializable 。而且,在事务的并发操作中可能会出现脏读,不可重复读,幻读。
- Read uncommitted
读未提交,顾名思义,就是一个事务可以读取另一个未提交事务的数据。 - Read committed
读提交,顾名思义,就是一个事务要等另一个事务提交后才能读取数据。 - Repeatable read
重复读,就是在开始读取数据(事务开启)时,不再允许修改操作。(MySQL 默认) - Serializable 序列化
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。- 与重复读的区别,个人理解:序列化是读写必加锁,两个事务完全互斥,不可能发生干扰。而重复读的要求没有那么严格(要弱上很多),要求在 A 事务期间,B 事务不会修改 A 事务所涉及的资源。
10. 如何提高服务器性能
单服务器的优化办法有:
- 使用内存数据库;
- 使用 RDD(Resilient Distributed Datasets);
- 增加缓存;
- 使用 SSD;
- 优化数据库;
- 选择合适的 IO 模型;
- 使用多核处理策略;
- 分布式部署程序。
分布式服务器的相关技术栈:
- 负载均衡(反向代理);
- 应用服务器集群;
- 数据库集群、读写分离;
- 动静分离;
- 缓存;
- 消息中间件;
- NoSQL;
- 分布式文件系统;
- 并行计算;
- 实时分析;
- 高可用、虚拟化、云计算;
- CDN
推荐阅读:
服务器性能优化的8种常用方法
11. 有关类加载器的几点思考
常见的类加载器有三种:
- BootStrap(引导):加载的基础文件,用 C 语言编写的。
- ExtclassLoader(扩展):同样加载基础文件,范围略大于 bootStrap。
- AppclassLoader(应用):加载 ClassPath 指定的所有 jar 和目录等。
如何获得类加载器?
- 由“字节码对象”(即内存中的 class),可以调 API 拿到其类加载器。
拿到类加载器能干什么?
- 可以通过类加载器读出 src 目录下的其他各种文件,主要读出各种配置文件如 properties 等。
1 | class clazz = class.forName("Mydemo"); |