
天猫Java一面
1. 常见集合类的区别和适用场景
List集合
ArrayList:
- 基于数组来实现集合的功能,内部维护了一个可变长的对象数组,集合扩容时会创建更大的数组空间,把原有数据复制到新的数组中。随机访问快,插入和删除的效率低。
LinkedList:
- 基于链表实现,数据的删除和插入快,随机访问的速度很慢。
####Map集合
HashMap:
- 线程不安全,存储键值对,允许 key 和 value 为 null
ConcurrentHashMap:
- 线程安全,不允许 key 和 value 为 null,使用的锁机制实现线程安全
TreeMap:
- 线程不安全,依靠comparator或comparable实现key的去重,TreaMap是有序的
2. 并发容器、同步容器
同步容器:同步容器将所有对容器状态的访问都串行化,以实现线程安全性。同步容器包括 Vector、HashTable。同步容器实现线程安全的方式是对每个公有方法都进行同步,使得每次只有一个线程能访问容器的状态。由于两个同步方法的操作顺序不一致,会引起数组越界,不安全。
并发容器:ConcurrentHashMap、CopyOnWriteArrayList、Queue、BlockingQueue、ConcurrentSkipListMap、ConcurrentSkipListSet。
3. ConcurrentHashMap、CopyOnWriteArrayList
ConcurrentHashMap:锁分段技术:容器中有多把锁,每把锁锁住容器的一部分数据,那么当多线程访问容器中的不同数据时就不存在锁竞争。
- concurrentHashMap 的结构是由 segment、hashEntry 组成。
CopyOnWriteArrayList:CopyOnWrite 容器即写时复制的容器。
- 通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器。写的时候需要加锁,不然多个线程同时写会有多个副本。CopyOnWrite 并发容器用于读多写少的并发场景。
4. 判断一个列表是否有环
两个指针,一个走的快,一个走的慢,最终经过若干步,走的快的指针总会超过慢的指针一圈而相遇。
1 | bool hasCycle(ListNode* head) { |
5. 多台服务器之间session共享方案
方案:
- session集中处理,建立一个数据库存放session,不同的应用从这个数据库中取session;
- 应用间session同步(缺点:网络间复制信息效率低);
- 将请求固定到对应的服务器,保证下次请求还是到达上次访问的服务器(即 session sticky 技术);
- 通过cookie中夹带的session,将session放在客户端。
6. BIO、NIO、AIO
BIO:阻塞IO,一个Socket套接字需要一个线程处理。
NIO:基于事件驱动思想,采用Reactor模式,统一通过Reactor对所有客户端的Socket套接字的事件做处理,然后派发到不同的线程。(线程与Socket是多对多的关系)。
AIO:异步IO,NIO在有通知是可以进行相关操作,AIO在有通知时表示相关操作已经完成
其实还有 IO 复用,信号驱动IO两种方式,具体参考:面经整理1
7. JVM内存模型
堆:主要存放对象实例,分为新生代、老年代,线程共享。
栈:主要存放局部变量,线程私有,方法调用的过程就是入栈到出栈的过程
方法区:线程共享,用于存放已被虚拟机加载的类信息、常量、静态变量、即使编译器编译后的代码等数据。
GC:引用计数法、可达性分析法。GC Roots:栈中引用的对象;方法区中类静态属性引用的对象,常量引用的对象;
8. Java的垃圾回收——标记算法和复制算法
标记算法:分为两个阶段:标记和清除。首先标记出所有需要回收的对象,在标记完成后统一回收。问题:效率不高;会产生内存碎片
复制算法:将内存按容量分成大小相等的两块,每次只用其中的一块,当一块内存用完了,就将还存活的对象复制到另一块上,清空已使用过的内存空间。内存的利用率变高,只有百分之十的空间被浪费。
9. http和https的区别,http1.x和http2.0的区别,SSL和TSL之间的区别
https在http的基础上加了ssl协议,ssl协议工作于传输层和应用层之间,为应用层提供数据的加密能力。
TSL:传输层安全协议,TLS可以理解成SSL协议3.0版本的升级,对于大的协议栈而言,SSL和TSL区别不大。
Http2.0实现多路复用、请求优先级、首部压缩、服务端推送
10. GC、G1、ZGC的区别
G1收集器:G1是一款面向服务端应用的垃圾收集器,特点:并行与并发(Stop The World)、分代收集、空间整合、可预测的停顿。G1收集器运作:初始标记、并发标记、最终回收、筛选回收。
ZGC:java11发布的新的GC收集器,缩短GC停顿,新技术:着色指针和读屏障
GC时方法论,G1、ZGC等收集器是具体实现。
11. B树、B+树、红黑树
12. 内存泄漏和内存溢出的区别
内存泄漏:是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积的后果就是内存溢出
内存溢出(OOM):是指程序申请内存空间时,没有足够的内存空间供申请者使用
栈溢出:如果线程请求的栈深度大于JVM 允许的最大深度,抛出异常
内存溢出解决方案:修改JVM启动参数,直接增加内存;找出可能发生内存溢出的位置。
13. session的生命周期
- session存放在服务器端,一般放在服务器的内存,session放在sessions容器中由Manager类管理,长时间不用的session将被回收,Tomcat中的默认失效时间是20分。
- 调用session的invalidate方法也会让session失效。
天猫Java二面
1. java cas原理
CAS包含三个操作数——需要读写的内存位置V,进行比较的值A和拟写入的新值B。
- 当且仅当V的值等于A时,CAS才会通过原子方式用新值B来更新V的值,否则不会执行任何操作。属于乐观锁。
2. Java线程池参数
7个参数
- corePoolSize表示常驻核心线程数;
- maximumPoolSize表示线程池能够容纳同时执行的最大线程数;
- keepAliveTime表示线程池中线程空闲时间,当空闲时间达到keepAliveTime时,线程会被销毁,直到剩下corePoolSize个线程为止;
- TimeUnit表示时间单位;
- workQueue表示缓存队列,当请求的线程数大于maximumPoolSize时,线程进入BlockingQueue阻塞队列;
- threadFactory表示线程工厂,用来生产一组相同任务的线程;
- handler表示执行拒绝策略的对象,当超过workQueue的任务缓存区上限的时候,就可以通过该策略处理器供求。
3. Java的lock的底层实现
- 继承AQS,AbstractQueuedSynchronizer会把所有的请求线程构成一个CLH队列,线程请求获取锁,如果获取失败会将线程信息封装成node加入Sync queue队列,循环请求获取锁。锁释放之后会唤醒队列中的第一个线程
- 当一个线程执行完毕(unlock)后,会激活队列中的后续结点。
- 原生 CLH 队列是自旋锁,但Doug Lea把其改造为阻塞锁。
lee补充:
####(0)调用顺序
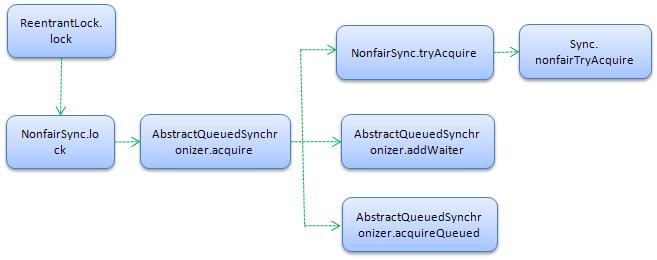
各种 Lock 的实现,都继承于
java.util.concurrent.*包下的AbstractQueuedSynchronizer类。以
ReentrantLock为例:1
2
3
4
5
6
7// ReentrantLock 的所有 Lock 接口的操作都委派到 Sync 上
static abstract class Sync extends AbstractQueuedSynchronizer
// 两个子类,公平和非公平锁
final static class NonfairSync extends Snyc
final static class FairSync extends SnycAQS 抽象了绝大部分 Lock 的功能,只把
tryAcquire()方法延迟到子类中实现。tryAcquire()方法在于用子类来判断,请求线程是否可以获得锁。- 参考博文:interview(1)的第八题
(1)加锁:
每次请求锁都会调用
nonfairTryAcquire()方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18final boolean nonfairTryAcquire(int acquires){ // acquires 初始为1
final Thread current = Thread.currentThread();
int c = getState();
if(c == 0){ // 说明当前没有锁竞争此资源
if(compareAndSetState(0,acquires)){ // CAS 的方式设置
setExclusiveOwnerThread(current);
return true;
}
}else if(current == getExclusiveOwnerThread()){
// 说明当前线程已经拥有此锁
int nextc = c + acquires; // 线程重入锁+1
if(nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc); // 实现了偏向锁的功能
return true;
}
return false;
}如果请求锁失败,那么新的竞争线程会被追加到队尾,具体采用 CAS 的 Lock-free 算法,因为线程并发对 tail 调用 CAS 可能会导致其他线程 CAS 失败,解决办法是循环 CAS 直至成功。
入队出队都是用CAS方式设置的,addWaiter 方法负责把当前拿锁失败的线程包装成一个 Node 添加到队尾,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34private Node addWaiter(Node mode){
Node node = new Node(Thread.currentThread(),mode);
Node pred = tail;
if(pred){ // 如果 tail 非空,将新的 node 置于 tail 处
node.prev = pred;
if(compareAndSetTail(pred,node){ // 追加队尾操作
pred.next = node;
return node;
}
}
enq(node); // 如果 tail 是空的,或者上一步的 CAS 失败,则执行 enq 方法
return node;
}
private Node enq(final Node node){
for(;;){ // 无限循环进行 CAS,知道把当前线程追加到队尾(或队头)
Node t = tail;
if(t == null){
Node h = new Node();
h.next = node;
node.prev = h;
if(compareAndSetHead(h)){
tail = node;
return h;
}
}else{
node.prev = t;
if(compareAndSetTail(t,node)){
t.next = node;
return t;
}
}
}
}执行
acquireQueued()方法,将刚追加到队列中的线程节点进行阻塞,但阻塞前再一次通过tryAccquire()重试是否能获得锁,如果重试成功则无需阻塞,直接返回,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 返回 false 表示可获得锁,无需入队
final boolean acquireQueued(final Node node,int arg){
try{
boolean interrupted = false;
for(;;){
final Node p = node.predecessor();
if(p == head && tryAcquire(arg)){
setHead(node);
p.next = null;
return interrupted;
}
if(shouldParkAfterFailedAcquire(p,node) &&
parkAndCheckInterrupt())
/* parkAndCheckInterrupt会调用 LockSupport.park() 显式阻塞,
* 此时进入系统内核中,检查线程状态(should...方法检查)
*/ 然后阻塞(park...方法阻塞)
// 被阻塞的线程经解锁后来到此步,将 interrupted 置为 true
// 解除阻塞状态的线程不一定能获得锁,仍需要参与竞争tryAccquire
interrupted = true;
}
}catch (RuntimeException ex){
cancelAcquire(node);
throw ex;
}
}
(2)解锁:
AbstractQueuedSynchronizer.release和Sync.tryRelease方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public final boolean release(int arg){
if(tryRealse(arg)){ // 如果可以释放锁,进入此判断
Node h = head;
if(h != null && h.waitStatus != 0)
unparkSuccessor(h); // 唤醒 head 线程(即队列第一个)
return true;
}
return false;
}
protected final boolean tryRelease(int releases){
int c = getState() - releases;
if(Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if(c == 0){
// 如果多次锁定,就多次释放,直到 c 为0才真正释放锁
free = true;
setExclusiveOwnerThread(null);
}
setState(c); // 因为没竞争,所以用不着 CAS
return free;
}
private void unparkSuccessor(Node node){
int ws = node.waitStatus;
if(ws < 0){
compareAndSetWaitStatus(node,ws,0);
}
Node s = node.next; // 一般 s 就是 head
// 如果head 是空(几率小),队列从后往前回溯,找到第一个可用线程
if(s == null || s.waitStatus > 0){
s = null;
for(Node t = tail; t!= null && t != node; t= t.prev)
if(t.waitStatus <= 0)
s = t;
}
if(s != null)
LockSupport.unpark(s.thread); // 通知系统内核唤醒该线程
}
(3)Lock 跟 Synchronized 底层比较
- 两者底层都是基于 CAS 操作的,从数据结构来说两者设计上没有本质区别。
- synchronized 实现了自旋锁,并针对不同的系统和硬件体系进行了优化;
- Lock 完全依靠系统阻塞挂起等待线程。
- Lock 比 synchronized 更适合在应用层扩展,可以既传承 AQS 定义各种实现,比如实现读写锁、公平、非公平锁等;Lock 比 wait/notify要方便的多、灵活地多。
Ps:Lock 的使用方法(四种锁法)可以参考这篇博文:Lock 的使用
【墙裂推荐阅读!】Lock 底层:Java锁—-Lock实现原理
4. mysql的数据库默认存储引擎
InnoDB:在使用MYSQL的时候,你所面对的每一个挑战几乎都源于ISAM和MyISAM数据库引擎不支持事务处理(transaction process)也不支持外键。尽管要比ISAM和 MyISAM引擎慢很多,但是InnoDB包括了对事务处理和外来键的支持,这两点都是前两个引擎所没有的。
MyISAM:除了提供ISAM里所没有的索引和字段管理的大量功能,MyISAM还使用一种表格锁定的机制,来优化多个并发的读写操作,其代价是你需要经常运行OPTIMIZE TABLE命令,来恢复被更新机制所浪费的空间,MYISAM强调了快速读取操作,MyISAM格式的一个重要缺陷就是不能在表损坏后恢复数据。
ISAM:因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源。ISAM的两个主要不足之处在于,它不支持事务处理,也不能够容错。
MyISAM引擎的索引结构为B+Tree,其中B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。
InnoDB引擎的索引结构同样也是B+Tree,但是Innodb的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。
5. Mysql的事务隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 是 | 是 | 是 |
| 读提交 | 否 | 是 | 是 |
| 重复读 | 否 | 否 | 是 |
| 串行化 | 否 | 否 | 否 |
脏读:
- 事务A读取了事务B更新的数据,然后B回滚操作,那么A读到的数据就是脏数据。
不可重复读:
- 事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
幻读:
- 系统管理员A将学生成绩分数改为ABCDE等级,这是系统管理员B插入一条学生成绩分数的记录,当系统管理员改结束后发现有一条记录没有更改,好像产生幻觉。
小结:不可重复读和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
6. 四个表 记录成绩,每个大约十万条记录,如何找到成绩最好的同学
创建索引,多线程查询,优化sql语句,提高查询效率
7. 常用的负载均衡算法
轮询、随机、源地址哈希、加权轮询、加权随机、最小连接数法
8. Redis持久化、keys命令
如果Redis有一亿个key,使用keys命令会影响性能,改为使用set(smemebers key)
redis持久化:http://redisdoc.zixuebook.cn/topic/persistence.html#redis
天猫Java三面
1. 大型网站的分布式服务器集群部署
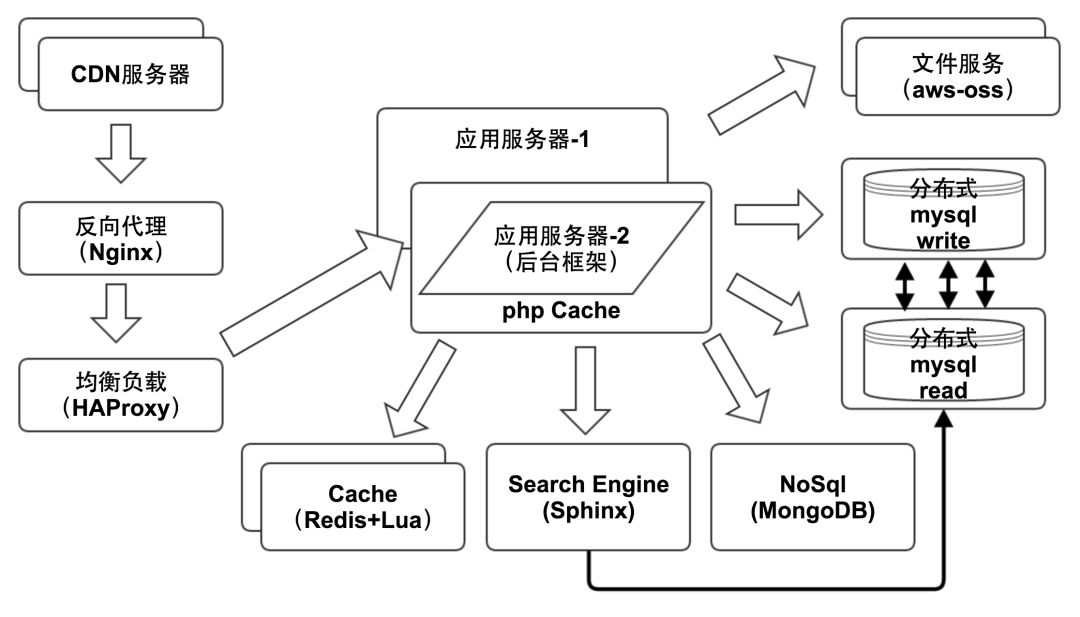
2. 多个RPC请求进来,服务器怎么处理并发
通过负载均衡策略,将请求分流;采用异步IO、非阻塞IO
3. Redis的哨兵机制(是一个分布式系统)
Redis的哨兵系统用于管理多个Redis服务器,该系统执行一下三个任务:
监控:Sentinel会不断地检查你的主服务器和从服务器是否正常运行
提醒:当被监控地某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发哦是那个通知
自动故障迁移:当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,他会将失效主服务器地其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主的服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
其他:
主观下线:指的是单个Sentinel实例对服务器做出的下线判断
客观下线:指的是多个Sentinel实例对服务器做出主观下线判断,并且通过SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。
(lee 总结:对主从服务器进行①运行监控 ②故障定位 ③故障转移 ④下线判断)
故障转移:
- 发现主服务器已经进入客观下线状态
- 对我们当前纪元进行自增,并尝试再这个纪元中当选
- 如果当选失败,那么在设定的故障迁移超时时间的两倍之后,重新尝试当选 ,如果当选成功执行以下步骤
- 选出一个从服务器,并将它升级为主服务器
- 向被选中的从服务器发送SALVE NO ONE命令,让他转变为主服务器
- 通过发布与订阅功能,将更新后的配置传播给所有其他Sentinel,其他Sentinel对它们自己的配置进行更新
- 向已下线主服务器的从服务器发送SLAVEOF命令,让它们去复制新的主服务器
- 当所有从服务器都已经开始复制新的主服务器时,领头Sentinel终止这次故障迁移操作
3. 数据库分库分表一般多大数据量才需要
一般来说,Mysql单库超过5000万条记录,Oracle单库超过1亿条记录,DB压力就很大,当数据量达到数据库所能承载的数据量后就需要分库、分表。单个库数据量(1T-2T)。
切库思路:读写分离,第一种自定义注解完成数据库切库,第二种项目中配置多个库的数据源(这几个数据库是完全不同的)。
数据库分表:横向分表、纵向分表(根据数据活跃度分离)mybatis分表插件shardbatis2.0
4. 如何保证数据库与redis缓存数据一致
首先尝试从缓存中读数据,命中则直接返回,如果读不到则到数据库读数据,并将数据写入缓存;更新数据时,先更新数据库,然后把缓存里对应的数据失效掉。
解决方案:定期全量更新,定期把缓存全部清掉,然后再全量加载;给所有的缓存一个失效期。
5. 消息队列的使用、应用场景
消息队列:解耦、异步、削峰。应用场景:解决应用解耦、异步消息、流量削峰
缺点:系统可用性降低、系统复杂度增加
6. JVM相关分析工具、具体的性能调优步骤
jstat、jinfo、jps、jstack、jmap
7. MySQL的慢sql优化
慢sql的原因:sql编写问题;锁;业务实例相互干扰;服务器硬件;MYSQL BUG
- 优化sql语句:通过慢查询日志,抓取慢sql,通过explain对慢sql分析。
- 字段类型转换导致不用索引,如字符串类型的不用引号,数字类型的用引号等,这有可能会用不到索引导致全表扫描;
- mysql 不支持函数转换,所以字段前面不能加函数,否则这将用不到索引;
- 不要在字段前面加减运算;
- 字符串比较长的可以考虑索引一部份减少索引文件大小,提高写入效率;
- like % 在前面用不到索引;
- 根据联合索引的第二个及以后的字段单独查询用不到索引;
- 不要使用
select *; - 排序请尽量使用升序 ;
- or 的查询尽量用 union 代替 (Innodb);
- 复合索引高选择性的字段排在前面;
- order by / group by 字段包括在索引当中减少排序,效率会更高。
- 除了上述索引使用规则外,SQL 编写时还需要特别注意以下几点:
- 尽量规避大事务的 SQL,大事务的 SQL 会影响数据库的并发性能及主从同步;
- 分页语句 limit 的问题;
- 删除表所有记录请用 truncate,不要用 delete;
- 不让 mysql 干多余的事情,如计算;
- 输写 SQL 带字段,以防止后面表变更带来的问题,性能也是比较优的 ( 涉及到数据字典解析,请自行查询资料);
- 在 Innodb上用 select count(*),因为 Innodb 会存储统计信息;
- 慎用 Oder by rand()。
- 最后,服务器的参数优化。
8. 秒杀场景的设计
特点:秒杀时网站的访问量大增;秒杀时购买的请求数量远小于库存,只有部分用户能够成功;业务流程简单,根据先后顺序,下订单减库存
前端:加验证码可以在单位时间内有效的控制住合法用户;将活动页面上的元素全部静态化,通过CDN抗峰值;禁止重复提交
后端:加缓存、限制uid、采用消息队列缓存请求、利用缓存应对读写请求