
部分题目来源:美团 java 后台 哈尔滨现场面试面经
1. 数据库主从同步、读写分离
主要用来提升数据库的并发负载能力。
- 数据的热备;
- 架构的扩展;
- 支持更大的并发;
主从复制的步骤:
- 从库生成两个线程,一个 IO 线程,一个 SQL 线程;
- IO 线程去请求主库的 binlog,并将得到的 binlog 日志写入 relay log 文件中。主库会生成一个 binlog dump 线程,用来给从库的 IO 线程传 binlog;
- binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息(查询不会有记录,只记录增删改)。在 my.cnf 中增加
log_bin参数即可开启。
- binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息(查询不会有记录,只记录增删改)。在 my.cnf 中增加
- SQL 线程,会读取 relay log 文件中的日志(从 Exec_Master_Log_Pos 位置开始执行),并解析成具体操作,来实现主从的操作一致,而最终数据一致。
缺点:
- 数据的实时性较差;
- 数据量大时,同步效率差;
- 同时连接多个数据库,容易引起混乱;
- 读具有高性能高可靠性和可伸缩。只读服务器因为没有写操作,大大减轻磁盘 IO 等性能问题;多个只读服务器可以采用负载均衡的方式实现可伸缩性。
- 写数据的分配一般采用哈希映射。
推荐阅读:
2. MySQL 上主从同步如何配置,工作原理
- 设置多个数据库服务器。
- 打开 master 上的 binlog,设置 slave 上的 relay-log。
- 将 master 和 slave 服务器关联起来,在 master 中执行:
1 | mysql> create user repl; |
- 创建一个数据库用户 repl,密码是 mysql,在 slave 中使用 repl 这个账号和 master 连接时,就赋予其 replication slave 的权限,
*.*表示这个权限是针对 master 的所有表,其中***就是 slave 的 ip 地址。 - 进入 slave 数据库后执行以下代码:
1 | mysql> change master to master_host='主xxx.xxx.xxx.xx',master_port=3306,master_user='repl',master_password='mysql',master_log_file='master-bin.000001',master_log_pos=0; |
Ps:上面的master_log_file='master-bin.000001'是配置 binlog 和 relay-log 后,执行SHOW MASTER STATUS命令后查到的。
- 此时在 master 数据库进行的操作,都会在 slave 库中执行了。
3. 线程的状态转换图
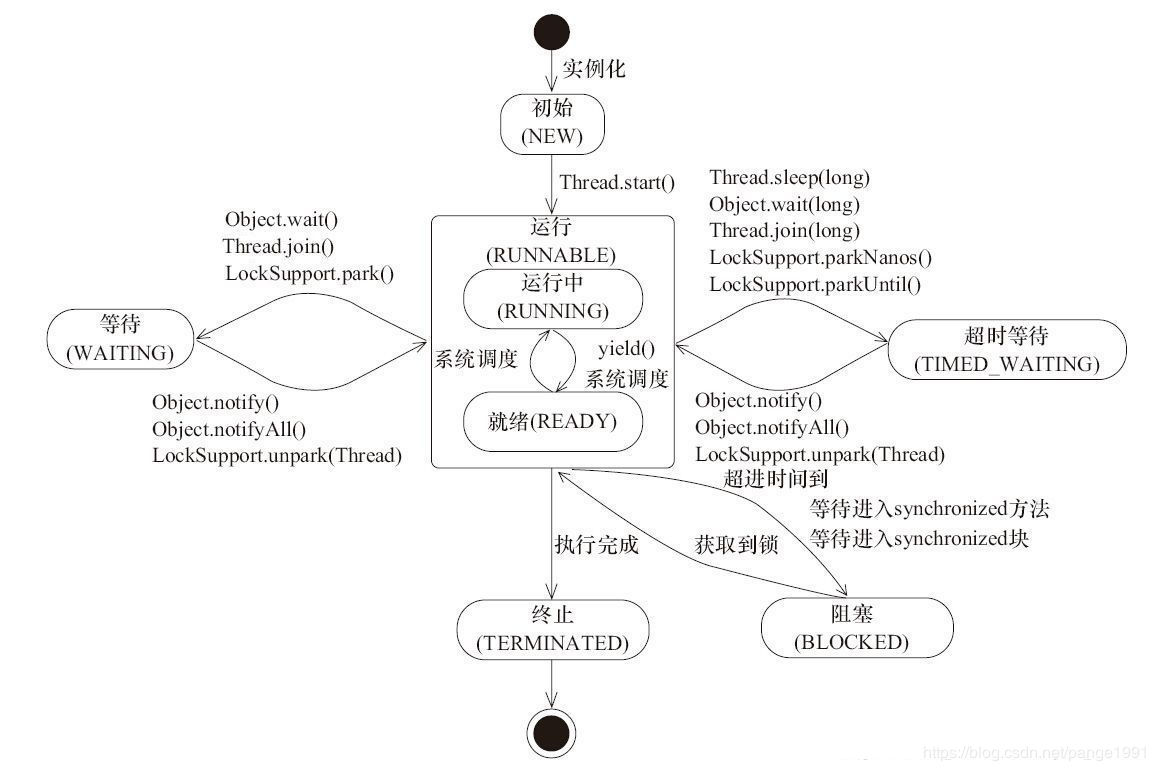
Java 线程具有六种基本状态:
- 初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
- 运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。
线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。 - 阻塞(BLOCKED):表示线程阻塞于锁。
- 等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
- 超时等待(TIMED_WAITING):该状态不同于WAITING,它可以在指定的时间后自行返回。
- 终止(TERMINATED):表示该线程已经执行完毕。
4. wait()和sleep()的区别
- wait():当前线程让出锁和同步资源,进入等待队列,等待调用 notify()/notifyAll()唤醒指定线程或者所有线程,被唤醒的线程需要重新参与线程的调度,而不会直接获得 CPU。而且,wait()方法只能在同步方法/块中使用。
- sleep():当前正在执行的线程休眠一段时间,主动让出 CPU,但是不让出锁和同步资源。到时间后,自动恢复,CPU 继续执行该线程。
5. 手撕代码:给定大小为n的数组,找出第K小的元素
首先看一个简单的:最坏情况下如何利用 n+logN-2 次比较找到n个元素中的第2小的元素?
采用 tournament method 算法:对数组a[1…n]中元素成对的做比较,每次比较后将较小的数拿出,形成的数组再继续这样处理,直到剩下最后的一个,就是数组中最小的那个。将这个过程以一个树的形式表现出来,如下图:
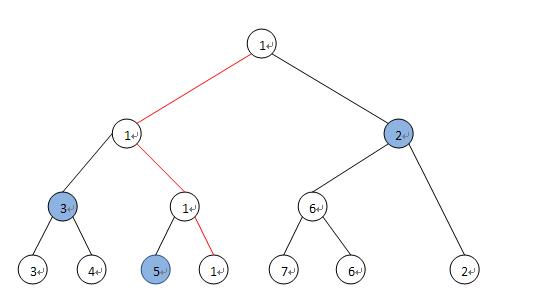
在这个过程中,非树叶节点就是比较的次数,一共进行了n-1次比较,树根即为最小的元素。而第二小的元素一定是在这个过程中与根节点进行过比较的元素。即上图中5,3和2。这样的节点最多有 logN 个,在这些节点中找到最小的元素需要进行-1次比较。因此总共所需的比较次数为n-1 +logN-1=n+ logN -2次。
长度为 n 的数组中,寻找第 K 小的元素
建大根堆。建立一个包含K个元素的最大堆,将后续的N-K每个数与堆顶元素比较,如果小于堆顶元素,则将其替换堆顶元素并调整堆得结构维护最大堆的性质,最后堆中包含有最小的K个元素,从而堆顶元素就是第K小的数。建堆的时间为O(K),每次调整最大堆结构时间为O(lgK),从而总的时间复杂度为O(K + (N-K)lgK)。
1 | /*得到第K小的数*/ |
6. 线程同步的方法
推荐阅读:Synchronized 同步静态方法和非静态方法总结
Synchronized 修饰非静态方法时,相当于对调用该方法的对象加锁。
- 同一个对象,在两个线程中分别访问该对象的两个同步方法,会产生互斥。
- 不同对象在两个线程中调用同一个同步方法,不会产生互斥。
Synchronized 修饰静态方法时,相当于对该类加锁。
- 用类直接在两个线程中调用两个不同的同步方法,会产生互斥。
- 用一个类的静态成员对象在两个线程中调用静态方法和非静态方法,会产生互斥。
- 一个类的普通对象在两个线程中分别调用一个静态同步方法和一个非静态方法,不会产生互斥。
同步方法:可以是静态和非静态方法,不可以是抽象和接口方法。
- 当一个线程调用这个对象的同步方法,则这个对象的其他所有同步方法将被锁定,不能被调用,但非同步方法可以被另外的线程调用。
7. spring 管理的controller是单例的,怎么实现的?
Spring 的 Controller 默认是 Singleton 的,这意味着每个 request 过来,系统都会用原有的 instance 去处理,这样导致了两个结果:
- 一是我们不用每次创建 Controller;
- 二是减少了对象创建和垃圾收集的时间。
- 由于只有一个 Controller 的 instance,当多个线程调用它的时候,它里面的 instance 变量就不是线程安全的了,会发生窜数据的问题。当然大多数情况下,我们根本不需要考虑线程安全的问题,比如 dao,service 等,除非在 bean 中声明了实例变量。因此,我们在使用 spring mvc 的 controller 时,应避免在 controller 中定义实例变量。
- 如果一定要使用成员变量,可以采用以下方式:
- 在 Controller 中声明 scope=”prototype” ,即设置为多例模式。
- 在 Controller 中使用 ThreadLoader 变量。
实现:因为 spring 的 controller 默认就是单例,所以当 spring 创建 applicationContext 容器时,spring 会先初始化所有的该作用域实例,加上 lazy-init 就可以避免预处理。
8. 为什么使用JDBC 时需要反射
- 通过反射获取
Class.forName("..Driver")所在线程的上下文类加载器(通常是系统类加载器)。 - 利用类加载器,加载数据库驱动并初始化,其中有个 boolean 判断。
- 判断通过,则返回 Connection(即数据库厂商提供的实例)。
主要原因:因为 JVM 双亲委托机制的限制,启动类加载器不可能加载得到第三方厂商提供的具体实验。有了线程上下文类加载器,启动类加载器(根加载器)反倒需要委托子类加载器去加载厂商提供的实现。
将父委托变成子委托的方式。
参考《Java 高并发编程详解》第11章 P178 详述
也可以参考面经整理5的第 2 题
9. mysql 中 char 和 varchar 的区别
- char 和 varchar 在存储和检索方面有所不同。
- char 长度为创建表时声明的长度(定长),长度值范围在 1 到 255。Varchar 存储可变长的字符数据。而且varchar 会用额外的字节来记录字符串的长度。
10. BLOB和TEXT有什么区别?
- BLOB是一个二进制对象,可以容纳可变数量的数据。TEXT是一个不区分大小写的BLOB。
- BLOB和TEXT类型之间的唯一区别在于对BLOB值进行排序和比较时区分大小写(即有排序规则和字符集),对TEXT值不区分大小写(即没有排序规则和字符集)。
- 简单说,如果要存储中文,就选 TEXT。
11. 什么情况下设置了索引但无法使用
- 以“%”开头的LIKE语句,模糊匹配
- OR语句前后没有同时使用索引
- 数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型)
12. 解释MySQL外连接、内连接与自连接的区别
- 先说什么是交叉连接: 交叉连接又叫笛卡尔积,它是指不使用任何条件,直接将一个表的所有记录和另一个表中的所有记录一一匹配。
- 内连接 则是只有条件的交叉连接,根据某个条件筛选出符合条件的记录,不符合条件的记录不会出现在结果集中,即内连接只连接匹配的行。
- 外连接 其结果集中不仅包含符合连接条件的行,而且还会包括左表、右表或两个表中的所有数据行,这三种情况依次称之为左外连接,右外连接,和全外连接。
- 左外连接,也称左连接,左表为主表,左表中的所有记录都会出现在结果集中,对于那些在右表中并没有匹配的记录,仍然要显示,右边对应的那些字段值以NULL来填充。
- 右外连接,也称右连接,右表为主表,右表中的所有记录都会出现在结果集中。
左连接和右连接可以互换,MySQL目前还不支持全外连接。
13. 悲观锁和乐观锁的 sql 实现
悲观锁:
1 | Begin Tran |
查询的时候使用了with (UPDLOCK)选项,在查询记录的时候我们就对记录加上了更新锁,表示我们即将对此记录进行更新。其他用户还可以查询此表的内容,但其他更新用户就会阻塞。
乐观锁:
1 | // 首先给表加一列 timestamp |
这便是乐观锁的解决方案,可以解决并发带来的数据错误问题,但不保证每一次调用更新都成功,可能会返回’更新失败’
14. spring MVC 和 Spring boot 的区别
SpringMVC:
- SpringMVC是Spring提供的一个强大而灵活的模块式web框架。通过Dispatcher Servlet, ModelAndView 和 View Resolver,开发web应用变得很容易。
- SpringMVC是一种基于Java的以请求为驱动类型的轻量级Web框架,其目的是将Web层进行解耦,即使用“请求-响应”模型,从工程结构上实现良好的分层,区分职责,简化Web开发。借助于注解,Spring MVC提供了几乎是POJO的开发模式,使得控制器的开发和测试更加简单。这些控制器一般不直接处理请求,而是将其委托给Spring上下文中的其他bean,通过Spring的依赖注入功能,这些bean被注入到控制器中。
- Spring框架最核心的就是所谓的依赖注射和控制反转。完全解耦类之间的依赖关系,一个类如果要依赖什么,那就是一个接口。至于如何实现这个接口,这都不重要了。只要拿到一个实现了这个接口的类,就可以轻松的通过xml配置文件把实现类注射到调用接口的那个类里。所有类之间的这种依赖关系就完全通过配置文件的方式替代了。
SpringBoot:
- Spring Boot引入自动配置的概念,让项目设置变得很容易。Spring Boot本身并不提供Spring框架的核心特性以及扩展功能,只是用于快速、敏捷地开发新一代基于Spring框架的应用程序,大部分的Spring Boot应用都只需要非常少量的配置代码,开发者能够更加专注于业务逻辑。
- Spring Boot只是承载者,辅助开发者简化项目搭建过程的。如果承载的是WEB项目,使用Spring MVC作为MVC框架,那么工作流程和SpringMVC的是完全一样的,因为这部分工作是Spring MVC做的而不是Spring Boot。
联系:
- Spring 最初利用“工厂模式”( DI )和“代理模式”( AOP )解耦应用组件。按照这种模式搞了一个 MVC 框架(一些用 Spring 解耦的组件),用开发 web 应用( SpringMVC )。
- 后来发现每次开发都要搞很多依赖,写很多样板代码,使代码臃肿而麻烦,于是聪明的前人整理了一些懒人整合包( starter ),这套就是 Spring Boot 。
区别:
- Spring MVC 是基于 Servlet 的一个 MVC框架 主要解决 WEB 开发的问题 但关于Spring 的配置比较 ;
- 而Spring boot 的原则是:约定优于配置 ,可以极大地简化了 spring 的配置流程。
15. 类加载机制中,什么时候进行静态变量的初始化
静态变量的初始化是在类被初始化时(类加载过程中的初始化阶段)进行的。而这个类,只有被首次主动使用时,才会被初始化。
主动使用的情况有六类:
- 通过 new 关键词。
- 访问类的静态变量(但 final 修饰的静态变量实质上是静态常量,不属于此范畴,不会初始化类)。
- 访问类的静态方法。
- 对类进行反射操作。
- 初始化子类会导致父类的初始化。
- 启动类。也就是 main 函数所在的类会被初始化。
参考本站另一篇博文:类加载机制笔记
16. 线程池的拒绝策略
- CallerRunsPolicy:线程调用运行该任务的 execute 本身。这个策略显然不想放弃执行任务。但是由于池中已经没有任何资源了,那么就直接使用调用该execute的线程本身来执行。
- AbortPolicy:处理程序遭到拒绝将抛出运行时 RejectedExecutionException。这种策略直接抛出异常,丢弃任务。
- DiscardPolicy:不能执行的任务将被删除。这种策略和AbortPolicy几乎一样,也是丢弃任务,只不过他不抛出异常。
- DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序。该策略就稍微复杂一些,在pool没有关闭的前提下首先丢掉缓存在队列中的最早的任务,然后重新尝试运行该任务。
17. GC Roots 有哪些?
所谓“GC roots”,或者说tracing GC的“根集合”,就是一组必须活跃的引用(而不是对象)
这些引用可能包括:
- 所有Java线程当前活跃的栈帧里指向GC堆里的对象的引用;换句话说,当前所有正在被调用的方法的引用类型的参数/局部变量/临时值。
- VM的一些静态数据结构里指向GC堆里的对象的引用,例如说HotSpot VM里的Universe里有很多这样的引用。
- JNI handles,包括global handles和local handles
- (看情况)所有当前被加载的Java类
- (看情况)Java类的引用类型静态变量
- (看情况)Java类的运行时常量池里的引用类型常量(String或Class类型)
- (看情况)String常量池(StringTable)里的引用