
1. Spring是怎么避免循环依赖的
循环依赖的问题:在DI时,如果有两个 class 类,都在 xml 文件中配置,但是如果 classA 是 classB 的属性,classB 同时也是 classA 的属性,那么该怎么处理呢?究竟先注入哪一个呢?
Spring是如何避免循环依赖的?
- 答:Spring基于Java的引用传递,我们获取到对象的引用时,对象的field或者属性是可以延后设置的。但Spring避免循环依赖有一个前提:那就是循环依赖不能发生在构造器中。
Spring 的单例对象的初始化主要分为三步:
- createBeanInstance实例化;
- populateBean填充属性;
- InitializeBean初始化。
循环依赖就是两个对象(设为A,B)在①②步时发生冲突的。
Spring使用了一个叫singletonFactories的三级cache机制,让本该发生A-B-A循环依赖中的B走到第①步时,可以拿到A(虽然A此时并不完整,仅走了①②两步),但足以让B能够走完剩下的②③步。B完成后,A可以继续完成自己的第③步。
推荐阅读:
2. 说说数据库的三大范式
第一范式:
- 无重复的列,数据库每一列都是不可分割的基本数据项。下面这种情况违反1NF:
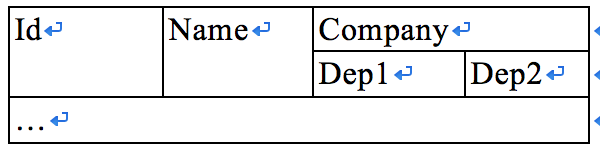
第二范式:
- 属性完全依赖于主键。每一列都与主键相关,而不能只与主键(联合主键)的某一部分相关。下面这种情况违反2NF:
- 存在关系:选课(学号,课程名,姓名,成绩)。其中主键为(学号,课程名),但是姓名仅与学号相关。违反2NF。
第三范式:
- 数据表中的每一列都和主键直接相关,而不是间接相关。下面这种情况违反3NF:
- 存在关系:学生(姓名,院系,学院主任)。其中姓名是主键,但学院主任与姓名是间接相关,违反3NF。
3. MyBatis中#{}和${}区别
${}:sql拼接符号。#{}:占位符号,好处防止sql注入。
- sql 预编译指的是数据库驱动在发送 sql 语句和参数给 DBMS 之前对 sql 语句进行编译,这样 DBMS 执行 sql 时,就不需要重新编译。
- ${ } 变量的替换阶段是在动态 SQL 解析阶段,而 #{ }变量的替换是在 DBMS 中。
- 先发生
${ },后发生#{ }
${}
仅为纯粹的String替换,在动态SQL解析阶段将进行变量替换(接受传参)
比如将Mapper.xml 下的:select * from user where name = ${name};如果传参为“Tom”,那么SQL解析后:
select * from user where name = "Tom";
#{}
解析为一个 JDBC 预编译语句(prepared statement)的参数标记符。
比如将Mapper.xml 下的:select * from user where name = #{name};动态解析为:
select * from user where name = ?; // 一个#{}被解析为?
用法:
- 能使用 #{ } 的地方就用 #{ }
- 表名作为变量时,必须使用 ${}
推荐阅读:MyBatis中#和$的区别
4. 建一个索引的SQL语句
方法一:ALTER TABLE,下面分别是创建普通索引、UNIQUE索引或PRIMARY KEY索引。
- ALTER TABLE table_name ADD INDEX index_name (column_list)
- ALTER TABLE table_name ADD UNIQUE (column_list)
- ALTER TABLE table_name ADD PRIMARY KEY (column_list)
方法二:CREATE INDEX,可对表增加普通索引或UNIQUE索引(不能增加主键索引)。
- CREATE INDEX index_name ON table_name (column_list)
- CREATE UNIQUE INDEX index_name ON table_name (column_list)
PS:column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。
两种方法的区别:
- 用方法1时,索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。一个语句可以建立多个索引。
- 使用方法二时,必须提供index_name,不能缺省。而且,一个语句只能建立一个索引。
推荐阅读:
mysql 添加索引,ALTER TABLE和CREATE INDEX的区别
5. 面试中的红黑树
推荐阅读:
6. JDBC 的预编译语句
- 没有预编译时,直接执行 Statement的情况(数据库引擎对 SQL 语句进行编译)。
- Statement 的 execute 系列方法直接将 SQL 语句作为参数传入并提交给数据库。每提交一次,都需要先编译再执行。
- 问题出现了:如果有需要重复执行的 SQL 语句,每次都要经过编译这样效率太低。
- 存在 SQL 注入隐患。
- 使用预编译语句的情况,使用 PreparedStatement 语句句柄,同时传入 SQL 语句。这里使用的预编译机制,如下:
- 支持占位符
?,可以等到后期再决定这些占位符具体的值(占位符只能站位普通值,不能站位表名、列名、SQL 关键字等)。 - 利用缓存机制(调用 getCachePreparedStatements()方法实现),将预编译语句语法与缓存中匹配,在有些时候可以不需再次编译即可直接执行。缓存的选择涉及到了使用频度等因素。
- 使用了预编译语句,传入的任何内容都不会和原来的语句发生任何匹配关系。
- 支持占位符
推荐阅读:
jdbc中预编译语句PreparedStatement的深层分析
JDBC:PreparedStatement预编译执行SQL语句
7. Linux进程管理的相关命令
1 | ##显示所有进程详细信息 |
推荐阅读:linux 进程管理相关命令汇总
8. 多线程的使用场景
- 常见的浏览器应用。
- Servlet多线程。(Servlet采用的是单实例多线程,参考:https://blog.csdn.net/hello5orld/article/details/19207053)。
- FTP下载,多线程操作文件。
- 数据库用到的多线程。
- 分布式计算。
- Tomcat 内部的多线程。
- 后台任务:比如后台批量发送邮件、监控任务等。
- 自动作业处理:比如定期备份日志,定期备份数据库。
- 异步处理:比如发微博、记录日志。
- 页面异步处理:比如大批量数据的核对工作(有10万个手机号码,核对哪些是已有用户)。
- 数据库的大量数据分析、数据迁移。
- 多步骤的任务处理,多任务分割。
- Desktop应用开发,前台进度条显示。
- Swing 编程。
推荐阅读:多线程的应用场景
9. 代码实现提取URL中传的参数和值,保存键值对
1 | import java.net.MalformedURLException; |
输出结果是:
1 | 18 |
PS:本题有多种实现方式,此处借助了java.net.URL 类的方法。
10. 代码实现N的平方根,不考虑四舍五入取平方根
使用牛顿迭代法获取 N 的平方根:
令f(x) = x^2 - N。方程的零根,就是所求的平方根。
步骤:
- 取一点
(Xn,f(Xn)),切线方程:f(x) = 2Xn*x - Xn^2 - N,切线与X轴交点((Xn + N/Xn)/2,0)(设为(Xn+1,0))。 - 根据牛顿迭代定理,Xn+1 是越来越接近目标值的,此处我们使用误差控制,来近似计算平方根。推荐阅读:牛顿迭代法计算平方根
1 | public static float sqrtRoot(float m ,float precise){ |
使用牛顿迭代法的常见限制条件:
- 函数在定义域最好是二阶可导的;
- 起始点对求根计算影响较大,可以增加一些别的判断手段先试错。
11. P2P 下载
BT种子有什么信息?
- 文件分块信息、分块哈希值(目的是下载时进行校验,防止恶意数据攻击)。此部分占空间大头。
- 中央服务器(问询服务器,tracker)的地址。
- 中央服务器的作用:记录节点服务器。
- 文件或者文件夹内每个文件的名字。
- 其他辅助信息。
读取 BT 种子下载的流程:
- 读取 BT 种子信息并载入内存。
- 告知问询服务器自己要下载,问询服务器会记录该客户端的公网IP。同时告知该客户端还有多少人也在下载这个文件(告知客户端有哪些 IP)。在下载过程中,需要 5 分钟跟 tracker 通信一次,如果太久不通信,tracker 会把这个客户端从节点列表中删除。
- 客户端拿到一堆 IP 后,会挨个尝试连接,连上了就开始互相通讯。
- 通讯内容告诉对方,比如我有哪些块、缺哪些块。
- 然后你来我往开始了下载。
辅助技术:
- DHT技术。如果 tracker 服务器连不上了,可以通过分布式哈希表 DHT 技术,在 DHT 网络中慢慢寻找志同道合的邻居节点。
- 与运营商的相爱相杀。
- BT 对磁盘的调度、缓存的机制、文件分块的调度算法、服务器对百万千万级别用户量的性能提升等。
推荐阅读:BT种子的原理是什么?
12. MySQL中有哪几种日志
MySQL中有以下几种日志文件:
- 重做日志 redo log
- 回滚日志 undo log
- 二进制日志 binlog(用于主从同步)
- 错误日志 errorlog
- 慢查询日志 slow query log
- 一般查询日志 general log
- 中继日志 relay log
推荐阅读:MySQL到底有多少种日志类型
13. LVS 的几种模型
// todo