
1. spring事务写在哪一部分,为什么不写在DAO,Controller层
事务写在Service层。
为什么不在DAO层?
- 在数据库中,所谓事务是指一组逻辑操作单元即一组sql语句。当这个单元中的一部分操作失败,整个事务回滚,只有全部正确才完成提交。
- 如果放在了DAO层,每一次增删改查都将提交一次事务,那么事务的一致性就会被破坏。
- 一般在Service的一处可以调用DAO层的多处,所以只要添加一处事务注解@Transactional,这样才能体现事务的特性。
为什么不在Controller层?
- 不推荐,但是事实上可以实现把事务放在Controller层。
- 一般不会将事务放在Controller层,而且直接放是会报404错误的(因为SpringMVC和Spring是两个不同的容器)。application.xml中应该负责扫描除@Controller的注解如@Service,而SpringMVC的配置文件应该只负责扫描@Controller,否则会产生重复扫描导致Spring容器中配置的事务失效。
@transactional可以注解到controller上吗?
在Spring MVC中,事务可以加在Controller层
【严重推荐!】Transaction 在 Controller 层的探索
2. 数据库驱动为什么使用反射调用不直接new
使用Class.forName("com.mysql.jdbc.Driver") 去加载驱动的目的:
- 用反射检查JDBC驱动的主类
com.mysql.jdbc.Driver是否存在,若不存在则表示运行环境中没有这个驱动,并进入catch段。用反射来加载的好处是,当驱动jar包不存在时,我们可以做更多的操作。 - 实现解耦。JDBC其实是JDK的一系列接口,对于不同数据库软件有不同的实现。使用反射后,代码中就不存在任何与实现相关的东西。如果直接用new,那么可能会引入
com.mysql.*或者com.oracle.*等,与代码耦合性高。
推荐阅读:JDBC为什么使用反射加载驱动
3. 观察者模式讲一下
- 是一对多关系的体现。
- 每个观察者Observer需要被保存到被观察者的集合中,并且被观察者提供添加和删除的方式。
- 被观察者把自己传给观察者(使用Observer自身的构造方法),当状态改变后,通过遍历和循环的方式逐个通知列表中的观察者。
- 虽然解耦了观察者和被观察者的依赖,让各自的变化不大影响另一方的变化,但是这种解耦并不是很彻底,没有完全解除两者之间的耦合。
推荐阅读:观察者模式
4. 多线程之Monitor
Synchronized关键字包括monitor enter和monitor exit两个JVM指令。
Monitor是一种同步机制。使用synchronized关键字时,同一时刻只能有一个线程访问同步资源,视为“加锁”。但实际上,是该线程获取了与mutex(互斥对象,即monitor object)相关联的monitor锁。
在JVM中,每一个对象都与一个monitor相关联,一个monitor的lock锁只能被一个线程在同一时间获得,在一个线程尝试获得与对象关联monitor的所有权时会发生如下的情况:
- 如果monitor的计数器为0,意味着该monitor的lock还没有被获得,某个线程获得之后将立即对该计数器加一,从此该线程就是这个monitor的所有者了。
- 如果一个已经拥有该monitor所有权的线程重入,则monitor计数器再次累加。
- 如果monitor已经被其他线程所拥有,那么某个线程尝试获取该monitor的所有权时,会被陷入阻塞状态知道monitor计数器变为0,才能再次尝试获取对monitor的所有权。
Wait()/notify()/notifyAll()方法构成监视条件(Monitor Condition)。
拥有monitor锁的线程可以调用wait()进入等待队列(Wait Set),同时释放监视锁,进入等待状态。
其他线程(有monitor锁的线程才有资格)调用notify()/notifyAll()方法唤醒等待队列中的线程,被唤醒的线程需要重新争取monitor锁。
推荐阅读:《Java高并发编程详解》P69 - P70
以及:Java 多线程(二)-Monitor
5. 如何使浏览器加载请求可以稳定到达后台而不使用浏览器缓存
Cache-Control/Pragma这个HTTP Head字段中进行缓存禁用:1
2Cache-Control: no-store
Cache-Control: no-cache, no-store, must-revalidateExpires字段,后面设置过期的日期和时间。Last-Modified/EtagLast-Modified字段,一般服务端在响应头中返回一个Last-Modified字段,告诉浏览器这个页面的最后修改时间,如Last-Modified:Sat,25Feb201212:55:04GMT,浏览器再次请求时在请求头中增加一个If-Modified-Since:Sat,25Feb 201212:55:04GMT字段,询问当前缓存的页面是否是最新的,如果是最新的就返回304状态码,告诉浏览器是最新的,服务器也不会传输新的数据。Etag字段,与Last-Modified字段类似。这个字段的作用是让服务端给每个页面分配一个唯一的编号,然后通过这个编号来区分当前这个页面是否是最新的。这种方式比使用Last-Modified更加灵活,但是在后端的Web服务器有多台时比较难处理,因为每个Web服务器都要记住网站的所有资源,否则浏览器返回这个编号就没有意义了。
推荐阅读:HTTP 缓存
6. eclipse、IJ开发快捷键及使用技巧讲几个
| Eclipse | Idea | |
|---|---|---|
| 格式化当前代码 | Ctrl+Shift+F | Ctrl+Alt+L |
| 注释当前行,再按取消注释 | Ctrl+/ | Ctrl+/ |
| 删除当前行 | Ctrl+D | Ctrl+X |
| 自动补全代码或者提示代码 | Alt+/ | Ctrl+空格 |
| 组织类的import导入 | Ctrl+Shift+O | Alt+空格 |
Eclipse使用技巧:
- 在Eclipse里文档生成是件简单的事情,只要键入“/**”,在一个声明上按enter键。
- 查看某个类的继承关系:选中该类,ctrl+t。
- 快捷键添加set、get方法,重写或实现接口的某个方法:shift+alt+s
Idea使用技巧:
- Ctrl+H 查看类的继承层次。
- Ctrl+Alt+B 可以跳转到抽象方法的实现。
- Ctrl-Shift-Backspace 让你调转到代码中所做改变的最后一个地方,多按几次 Ctrl-Shift-Backspace 查看更深的修改历史。
- 使用 Ctrl-Shift-V 快捷键可以将最近使用的剪贴板内容选择插入到文本。使用时系统会弹出一个含有剪贴内容的对话框,从中你可以选择你要粘贴的部分。
- Ctrl-D 可以复制选择的块或者没有所选块是的当前行。
7. classPath 与path的区别
- Path环境变量,作用是指定命令搜索路径。
- 比如,在命令行下 javac helloWorld.java,那么将从Path路径下找这个java文件。
- 如何来做:把jdk安装目录下的bin目录增加到现有的PATH变量中(bin目录下有常用的javac/java/javadoc等命令)。
- ClassPath环境变量,作用是指定类搜索路径。
- JVM就是通过CLASSPTH来寻找类的。
- 如何来做:需要把jdk安装目录下的lib子目录中的dt.jar和tools.jar,以及当前目录“.”一并设置到CLASSPATH中。
- JAVA_HOME环境变量,指向jdk的安装目录。
- Eclipse/NetBeans/Tomcat等软件就是通过搜索JAVA_HOME变量来找到并使用安装好的jdk。
推荐阅读:环境变量path和classpath的作用是什么?
8. Linux 的软链接、硬连接
先看三个概念,文件数据块、元数据、inode号,解释如下:
- 文件数据块(data block),也称为用户数据(user data),是记录文件真实内容的地方。
- 元数据(metadata),属于文件的附加属性,记录着“文件大小、创建时间、所有者”等信息。也包括了inode号。
- inode号,是文件的唯一标识(文件名不是唯一标识),使用inode号来查找正确的文件数据块。(流程:filename -> inode -> data blocks)。
- 在 linux 中,可以使用命令
ls -i查看 inode。 - 移动命令
mv和重命名,并不会改变文件的“文件数据块”和 inode 号。
- 在 linux 中,可以使用命令
重点来了,硬链接与软链接,如下:
- 硬链接 hard link:同一个文件使用的多个别名。此时的多个 link 有着共同的 inode 及 data block,仅文件名不相同。
- 可以用命令
link或ln创建,后跟-d。 - 只能对已存在的文件进行创建;
- 不能交叉文件系统创建硬链接;
- 只能对文件创建,不能对目录进行创建;
- 删除硬链时,不会影响其他有相同 inode 号的文件。
- 可以用命令
- 软链接 soft link 或者 symbolic link:若文件的文件数据块中存放的内容是另一个文件的路径名的指向时,这个文件就是软链接。软链接就是一个普通文件,只是数据块内容有点特殊,它有自己独有的 inode 号以及文件数据块。
- 可以用命令
ln -s来创建; - 有自己的文件属性及权限;
- 可对不存在的文件或目录创建软链;
- 可交叉文件系统;
- 创建软链时,链接计数
i_nlink不会增加;- 简单来说,
i_nlink是一个inode中统计 hard link 数量的计数器
- 简单来说,
- 删除软链不会影响被指向的文件,但如果被指向的原文件被删,则相关软链被称为死链。
- 可以用命令
软链接举例:
1 | # ln -s 目标地址 快捷方式地址(放在 /usr/local/bin/ 目录下可以直接启动) |
推荐阅读:理解 Linux 的硬链接与软链接
9. Spring 中 bean 的生命周期
在 Spring 中,bean 的生命周期完全由容器控制。
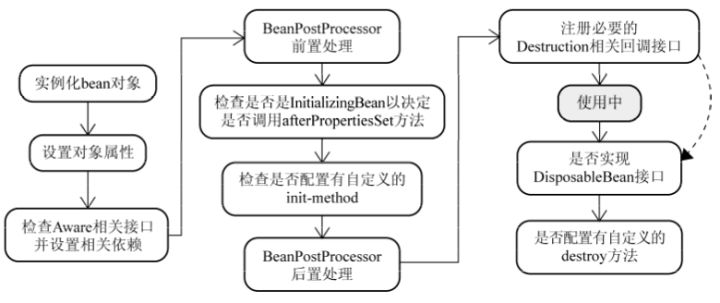
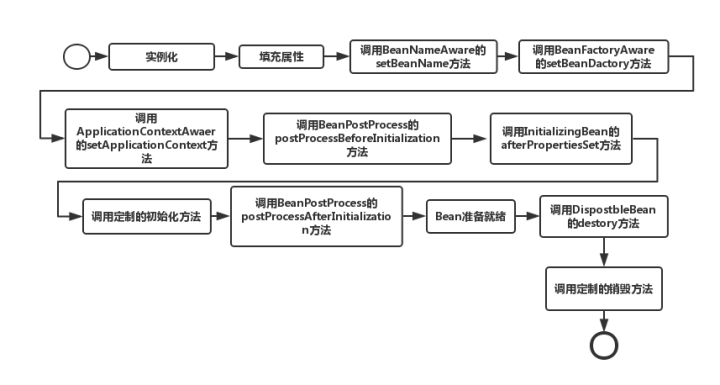
最简理解(阉割版):
- 实例化bean;
- DI;
- 前置、后置处理;
- 使用;
- 销毁。
10.Mybatis批量查询手写sql
- 情况1,传入是一个集合时(如一个装着 id 的 List )如下:
1 | // Mapper.java |
- 情况2,传入的是一个 Map时(Map 有一个<String,List>的键值对)如下:
1 | // Service |
- 情况3,传入的是一个对象时(比如对象中有一个 list 集合及 getter、setter 方法)如下:
1 | // Service |
ps :Mybatis 中的 resultType 与 resultMap的区分:
resultType 是直接表示返回类型的 ,resultMap 则是对外部 ResultMap 的引用(旁边一定有个 ResultMap 的元素)。resultType 与resultMap 不能共存。
当提供的返回类型属性是
resultType时,MyBatis会将Map里面的键值对取出赋给resultType所指定的对象对应的属性。所以其实MyBatis的每一个查询映射的返回类型都是ResultMap,只是当提供的返回类型属性是resultType的时候,MyBatis对自动的给把对应的值赋给resultType所指定对象的属性。当提供的返回类型是
resultMap时,因为Map不能很好表示领域模型,就需要自己再进一步的把它转化为对应的对象,这常常在复杂查询中很有作用。使用 resultMap 的简单查询与复杂查询:1
2
3
4
5
6
7
8
9
10
11
12
13<!--简单查询-->
<!--通过“BlogResult”进行映射-->
<resultMap type="Blog" id="BlogResult">
<id column="id" property="id"/>
<result column="title" property="title"/> <!--如果不写这些映射,Mybatis也会自动帮封装-->
<result column="content" property="content"/>
<result column="owner" property="owner"/>
</resultMap>
<select id="selectBlog" parameterType="int" resultMap="BlogResult">
select * from t_blog where id = #{id}
</select>
- 复杂查询就不写代码了,可能涉及到子节点、关联查询等,太复杂,建议直接看下面的链接。
推荐阅读:Mybatis中的resultType和resultMap
11. JVM、Tomcat与进程之间你需要知道的事情
- 一个 JVM 就相当于一个操作系统(实质是一个进程)。
- JVM 的生命周期:一个 Java 程序开始执行时,JVM 才运行;程序结束时它停止执行。
- 一个 Java 应用程序会开启一个 JVM 进程,如果运行了三个程序,那么会有三个运行中的 JVM 进程。
- JVM 运行 Java 程序有两种方式:jar 包和 Class:
- 运行 jar 时,先拿 JNIEnv 实例,然后拿 Manifest 对象,最后拿 jar 中的文件(拿主类),然后装载该主类。
- 运行 Class 时,main 函数直接调用 Java.c 中的 LoadClass 方法装载该类。
- Tomcat 是一个 Java 程序,是一个用 Java 语言开发的免费开源的 Web 服务器。
- Tomcat 与 Java 应用程序(webapps 目录下的 war 包)是运行在同一个 JVM 中,但是分工不同,Tomcat 相当于调度员,Java 程序相当于工人。Tomcat 处理请求的步骤如下:
- Tomcat 监听8080端口(假设),一个 http 请求从主机的 8080 端口发送过来,Tomcat 最先获悉;
- Tomcat 将该请求放入一个队列中,JVM 中有若干工作者线程会从此队列中获取任务;
- 假设线程 A 取得此任务,A 会分析请求的 url,并检查已加载的 Web.xml 配置,来判断要将此请求交给应用的哪个 servlet 来处理(假设应用由 servlet 来实现的);
- 此时应用开始干活,解析请求参数,处理业务流程,生成响应;
- 线程 A 把 response 回送给请求的发送端。
- Tomcat 与 Java 应用程序(webapps 目录下的 war 包)是运行在同一个 JVM 中,但是分工不同,Tomcat 相当于调度员,Java 程序相当于工人。Tomcat 处理请求的步骤如下:
推荐阅读:Java JVM 运行机制及基本原理
tomcat 和 jvm 的关系
12. 通过 Class 对象获取方法集合的三种方法的区分
- getDeclaredMethods: 获得声明的所有方法(protected、private、default、public,但不包含继承的方法)。
- getMethods:获得所有 public 方法,包括继承类的 public 方法(即父类的 public 方法)。
- getMethod:传入方法名(以及参数表对应的多个 class,比如 int.class),获取该方法
推荐阅读:深入解析Java反射(1) - 基础
13. 如果排序 10G 的元素
问题:不能一次性放入内存中,所以需要引入外部排序。
- 数据源读一批数据到缓冲区;
- 缓冲区中读取一批数据到内存;
- 内存进行堆排序(或使用Priority Queue)。
Iterable