
Redis 专题
1. 为什么要用 redis 而不用 map/guava 做缓存,Redis 跟 Memcached 的区别
- 因为缓存分为本地缓存和分布式缓存,map/guava 属于本地缓存,Redis/Memcached 属于分布式缓存。
- 本地缓存特点:轻量、快速,生命周期随 JVM 销毁而结束;在多实例下,每个实例保存着独立的缓存,相互不一致。
- 分布式缓存特点:在多实例下,各实例共用一份缓存,具有一致性;要维护分布式服务高可用,程序架构复杂。
Redis 与 Memcached 区别:
Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 是单线程,多路 IO 复用的网络模型。
Memcached 只支持 String 类型;Redis 支持更丰富的数据类型(主要五种,String、hash、list、set、zset)。
[官网] It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams
Memcached 将数据全部存在内存中;Redis 支持数据的持久化。
Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;Redis 是原生支持 Cluster 模式的。
2. 如何解决 Redis 的并发竞争 Key 问题
并发竞争key问题,主要是并发写的问题
有五种解决方案:
使用 redis 自带的 incr 命令:
- incr 和 expire 操作用 lua 脚本执行,保证原子性,代码实现。
- 如果有其他原子性命令需求,可以通过 lua 脚本自己创建。
[官网]Redis guarantees that a script is executed in an atomic way: no other script or Redis command will be executed while a script is being executed. This semantic is similar to the one of MULTI / EXEC
使用独占锁的方式,实现复杂,成本较高。
使用乐观锁的方式,使用 watch 监视键是否被修改。
针对客户端使用,在代码中对 redis 操作时,针对同一 key 的资源要先加锁。
利用 redis 的 setnx 实现内置的锁。
推荐阅读:Redis 的并发竞争问题的解决方案总结
3. 设置 key 的过期时间
1 | redis> SET key yes |
4. Redis 的用途小结
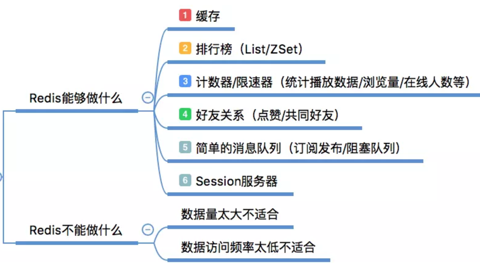
- 用作缓存。
- 排行榜,使用 SortSet 数据结构。
- 计数器,使用 Redis 中原子性的自增操作;限速器,限制某用户访问某 API 的频率。
- 好友关系,利用集合中交集、并集、差集的操作。
- 简单消息队列,可以使用 Redis 的订阅/发布模式,或者 List 来实现。
- Session 共享
不适合 Redis 的地方:
- 使用 Redis 去保存用户的基本信息,因为其持久化方案并不能保持数据绝对的落地,而且持久化频率若过高可能会降低 Redis 的效率。
- 数据量太大,数据访问频率较低的场合不适合使用 Redis,因为这些数据一直放在内存中会造成资源的浪费。
5. Redis 的有序集合主要由跳表来实现
[理解]跳表:对于单链表而言,线性查找的时间复杂度很高,是 O(n)。从链表中每隔几个结点提取出一层索引,可以在索引的基础上继续提取一层索引,如此下去直到索引中只有少数几个结点(比如只留两个结点),这种做法的时间复杂度是 O(logN),空间复杂度是 O(N)。时间复杂度与二分法、红黑树相当。
跳表的插入和删除的时间复杂度也是 O(logN)。当插入过多而不更新索引时,跳表的效率会降低,所以需要进行“平衡性”的维护,这里用到了随机函数的做法。使用随机函数,来决定将这个结点插入到哪几级索引中。
Redis 中为什么采用跳表,而不是红黑树:
- Redis主要操作有:插入、删除、查找、按区间查找、迭代输出。
- 除了按区间查找外,其他几项跳表与红黑树都能完成,而且时间复杂度一致。
- 按区间查找,红黑树效率不如跳表。
6. Spring 配置 Redis 注解缓存
【一定要看这篇博客!!!超牛批】spring配置redis注解缓存和spring+redis的集成,redis做缓存