
ARTS 第一周分享
每周完成一个ARTS(也就是 Algorithm、Review、Tip、Share 简称ARTS):
- 每周至少做一个 leetcode 的算法题
- 阅读并点评至少一篇英文技术文章
- 学习至少一个技术技巧
- 分享一篇有观点和思考的技术文章
Algorithm
LeetCode 229. Majority Element II
1 | // Time complexity:O(n). |
1 | // 邻接表版的图的 DFS |
Review
本周阅读的英文文章是:Understanding CPU cache friendliness
文章主题:CPU 缓存的知识
主要内容:
- 对于一个空序列,有一组乱序的数字要插入这个序列中,逐个插入时都要保证有序。满足上面情况的序列其实有两种实现:数组及链表。
- 起初两种实现的耗时表现基本一致,但随着元素数量的增加,数组实现明显比链表实现完成地更快(即便插入删除数据会造成数组元素的大量移动,数组仍然更快),这种差异其实是由 CPU 缓存造成的。
- 根据摩尔定律,我们知道处理器中晶体管的数量每 18 个月会翻一倍,但是最近的单核CPU表现却是十分平缓,为了增加处理速度只好增加更多的核。然而,RAM 的发展速度要远远地慢于CPU。
- 从缓存中取一个line可能需要 100ns,但是这100ns里,CPU甚至可以执行1200条指令。
- 回到上文数组和链表的问题。首先,数组存储一个整数需要4个字节,而链表需要16个字节,链表要访问更多的内存区域才能完成;其次,链表的物理存储位置分散,访问时相对“随机”,会导致 CPU 缓存失效(个人理解:CPU 会缓存物理区域相近的数据,随机访问时不容易命中缓存)。最后,硬件也更倾向于访问物理结构在一起的内存,例如数组结构。
- 结论:
- 非必要时,不要存储数据;
- 尽量有规律地访问数据;
- 考虑算法复杂度时,也要考虑稳定性,众所周知,快排、归并、堆排的时间复杂度都是O(NlongN),快排虽快,但它的稳定性最差。
Tip
本周介绍两个效率工具,都是 chrome 浏览器的插件—— Stylus 和 Octotree。
- 先说第一个:Stylus 插件,是一种网页外观样式管理器。像 CSDN 这类热点网站的布局实在难看即可,旁边的广告、琐碎信息太多容易分散精力,使用此插件之后,可以选自己舒服的样式,比如把正文框加宽等, 效果如下:
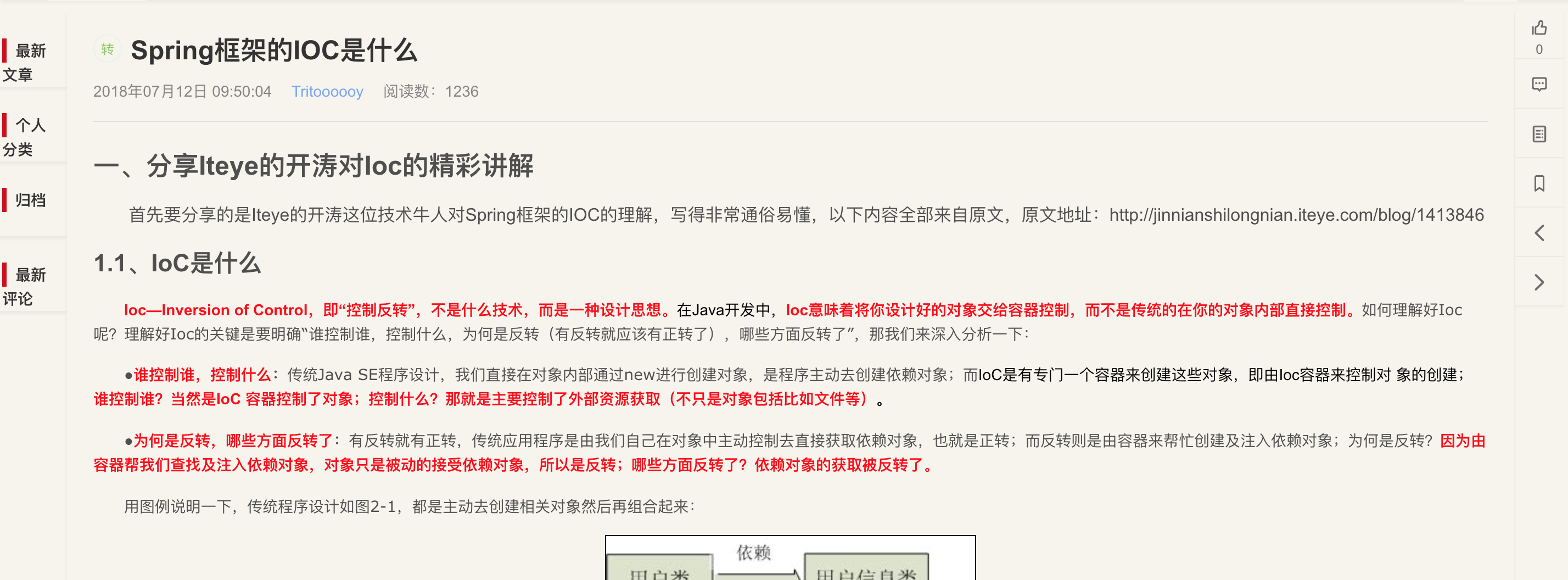
- 然后说第二个:Octotree 插件,是专门用在 GitHub 网站上的,可以在浏览器一侧显示目录结构,爽到起飞,效果如下:

Share
本周主要在准备 Java 实习生面试,Share 环节打算系统地整理一下有关 ConcurrentHashMap(JDK 1.8) 的面试知识点。
分为以下几个小节:
- 前置知识
- 什么是 ConcurrentHashMap?
- 它的线程安全的体现。
1. 前置知识
1. 首先我们需要知道 HashMap 这个基础类的存在。基础功能就不说了,直接看扩容操作:
HashMap 的扩容:
先涉及两个参数:newCap 和 newThreshold,newCap 通常是原来的2倍,阈值(Threshold)也变为原来的2倍。
扩容后要将键值对Hash的重新计算,然后移动到合适的位置上去,如下:
- 在链表中,如果
e.hash & oldCap == 0,则保持在原本的位置上,并且相同计算结果的结点按原来的相对位置接在后面。 - 如果
e.hash & oldCap == 1,则这些结点都要放在原位置j + oldCap 的位置上,这些结点相对位置不变。 - 在红黑树中,如果需要扩容操作,红黑树也需要拆分后重新映射。研究拆分之前,建议先阅读下边的扩展内容——红黑树的树化步骤。现在说一下拆分过程:因为红黑树中保留了原链表结点的 next 指针,所以分组方式跟原链表完全相同,将分成两种不同的链表。
- 红黑树拆分后变成两个链表,长度自然会变短,如果长度小于等于 6 ,那么此半个红黑树将保持链表状态;如果长度超过 6 ,那么将继续树化,成为一颗红黑树。
扩展:红黑树的树化步骤,如下:
- 在链表中,如果
- 将链表普通结点改造成 TreeNode 树形节点链表;
- 将得到的链表转化成红黑树。
- 形成红黑树时需要比较结点间的大小:① 首先比较 hash 的大小;② 如果相等,则检查键类是否实现了 Comparable 接口,若是则调用 compareTo 方法进行比较;③ 若仍无法比较大小,则调用
tieBreakOrder()方法进行仲裁,仲裁后就有大小的区别了。 - 链表转红黑树后,原链表的连接顺序依旧被保留了下来(next 指针来实现)。
- 形成红黑树时需要比较结点间的大小:① 首先比较 hash 的大小;② 如果相等,则检查键类是否实现了 Comparable 接口,若是则调用 compareTo 方法进行比较;③ 若仍无法比较大小,则调用
2. 然后需要知道Unsafe 类
Unsafe 类能够对内存进行操作,详细功能如下:
- 内存的操作。以下主要讲解直接内存:通过Unsafe.allocateMemory分配内存、Unsafe.setMemory进行内存初始化,而后构建Cleaner对象用于跟踪DirectByteBuffer对象的垃圾回收。
- CAS 操作。代码可参考上一题——Atomic 源码细节。其中调用的
compareAndSwap*才是真正的原子操作,CAS#getAndAddInt()是在原子操作的基础上增加了自旋的逻辑。 - 线程调度。
Java锁和同步器框架的核心类AbstractQueuedSynchronizer,就是通过调用LockSupport.park()和LockSupport.unpark()实现线程的阻塞和唤醒的,而LockSupport的park、unpark方法实际是调用Unsafe的park、unpark方式来实现。
- 内存屏障。其实是 CPU 或者 IDE 对内存随机访问的一个安全点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作,避免代码重排序。体现在 Unsafe类中的
*Fence()系列方法 - Class 操作。不展开,直接看原博客。
- 对象操作。主要应用场景是:非常规的对象实例化方式(比如绕过类构造器,绕过安全检查等)。
- 数组相关。主要跟 AtomicIntegerArray中的数组操作中的元素定位有关。
- 系统相关。系统指针大小(32位指针大小是4B,64位是8B);内存页大小(作者主机上内存页大小是4096B)。
在 ConcurrentHashMap 中主要涉及三个操作:
tabAt()用来返回节点数组的指定位置的节点的原子操作。casTabAt()cas原子操作,在指定位置设定值setTabAt()原子操作,在指定位置设定值
2. 什么是 ConcurrentHashMap?
ConcurrentHashMap 基础功能的实现原理跟 HashMap 相近,但 ConcurrentHashMap 是 HashMap 的线程安全的实现,内部使用了大量的 CAS、volatile、Synchronized 等并发技术,在 Spring 框架中被广泛应用。
3. 线程安全的操作
3.0 关于sizeCtl 变量
sizeCtl 数值:
- -1 :代表table正在初始化,其他线程应该交出CPU时间片
- -N: 表示正有N-1个线程执行扩容操作(高 16 位是 length 生成的标识符,低 16 位是扩容的线程数,最大 65535)
- 大于 0: 如果table已经初始化,代表table容量,默认为table大小的0.75,如果还未初始化,代表需要初始化的大小
3.1. 初始化操作:
首先有一个执行“初始化操作”的线程,然后观察 sizectl 参数,如果小于 0 ,此线程自旋等待;如果大于等于 0 ,则利用 CAS 操作将其设为 -1,此 CAS 操作保证以下操作的线程安全:① 为数组开辟内存,② 将 sizeCtl 设为数组长度的 3/4(即sc = n - (n >>> 2))。
1 | // 初始化完整源码: |
3.2. put 操作
- 先拿到欲添加的 key 的 hash(执行
(h ^ (h >>> 16)) & HASH_BITS;)。 - 若 table 还没有申请到内存,则先执行初始化操作,即本题上一节。
- 若将要放置的位置没有元素,会执行
casTabAt()方法尝试添加。 - 若检测到当前元素的hash为moved状态(说明正在执行
transfer()操作,此操作会调用ForwardingNode()方法,此方法会将元素的hash设置为moved)。说明正处于数组扩张的数据复制阶段,则此线程也会参与去复制即helpTransfer,通过允许多线程复制的功能,以此来减少数组的复制所带来的性能损失。 - 若当前位置有元素,则使用 Synchronized 的方式加锁,对以下操作进行线程安全控制:① 若是链表,遍历链表,若同hash同key,则替换该value;不然,新建node加到链表末尾。② 若是红黑树,则添加到红黑树中。
3.3. get操作
get 操作无锁,支持并发
3.4. 链表转树操作
- 在执行
treeifyBin()转树方法时,若桶的数量小于 64 时,优先触发扩容操作,细节参考本题下一节:3.5 扩容操作。 - 若桶数量多于 64 时,使用Synchronized 方式加锁,对以下操作进行线程安全控制:① 将普通结点转换为 TreeNode 结点;② 将 TreeNode 组成的链表构造出 Treebin 对象,在 Treebin 对象的构造方法中,链表被转换成了红黑树。
3.5. 扩容操作
首先调用tryPresize()方法(支持并发),确定扩容的目标值(决定扩容的次数),以及根据sizeCtl参数选择进入不同的分支。
最终来到transfer方法处。
- 首先如果多线程一起进行扩容操作,那么每个线程最少处理 16 个长度的数组元素,以避免此方法占用过多的 CPU 使用。
- 第一个进入扩容的线程负责初始化一个新的table,长度是旧的两倍。
- 然后分配一个区间的桶(一般是16 个)给此线程,完成下标的控制。
- 如果扩容结束,可以尝试领取新的区间;如果无法领取,那么 sizeCtl 减一,扩容的线程减少一个。
- 如果数组i处桶是空的,就尝试用 CAS 占位,将占位符 fwd 插入。
- 如果桶不是空,而且已经有了占位符,说明已有其他线程处理过此操作,那么当前线程将跳过这个桶。
- 如果以上都不是,而且扩容操作没有完成,那么将开始同步处理这个桶。
- 处理每个桶的行为是同步的,使用Synchronized关键词修饰,剩下的操作与HashMap基本一致,不再赘述。
That’s all,thank you!