
深度学习名词辨析
本文参考自:《Python 深度学习》2018 版
本文也会进行系列更新
注:以下名词并不权威,多是以直白的语言阐述的个人理解,仅供参考。
- 经典的程序设计:input:规则和数据,output:答案。但机器学习是一种新的编程范式:input:数据和答案,output:规则。
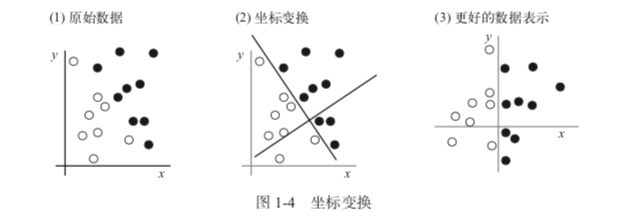
- 表示:input 数据的有用表示(即某种表现方式,通过变换数据做到,目的是使 input 更适合当前的任务)。机器学习模型就是为了能够为 input 的数据自动寻找到合适的表示。例:坐标变换,见下图:
4. 操作空间:自动寻找表示的过程,通常只能是遍历一组预定义好的操作,这组操作就是假设空间。
1. 利用反馈信号来寻找哪个操作更有效。
- 每个操作使用”权重”,即一串数字,来进行参数化。
5. 深度学习:一系列连续的表示层,深度从数十层到数百层不等。
1. 分层通常由**神经网络**的模型来学习得到。[理解]分层可以类比为多级蒸馏,每次蒸馏后,信息纯度越来越高,信息价值也就越高。
2. 深度学习能够让特征工程自动化。
3. 模型在同一时间共同学习所有的表示层,而不是依此连续学习。并且使用单一反馈信号来监督。
6. 学习:将预期 output 跟当前 output 的差距进行比较得出衡量结果,进而优化算法。
1. 学习的目的就是,为神经网络的所有层找到一组权重值,使得每个 input 都能够获得目标 output。
结果的衡量方式:使用神经网络损失函数(loss function),也叫目标函数。损失函数的 input 是预测值跟真实值,output 就是一个其偏差,偏差会转化为一个距离值。
优化过程:将距离值作为反馈信号,对权重值进行微调,以降低偏差。这种调节由优化器optimizer完成,实现了所谓的反向传播backpropagation。
支持向量机SVM的目标:解决分类问题,为两个不同类别的两组数据点之间找到良好的决策边界。做法:
1. 数据映射到新的高维表示,决策边界用一个超平面来表示; 2. 尽量让超平面与每个类别最近的数据点之间的距离最大化。- SVM 缺点:难以计算。
- 缺点的应对办法:使用 kernel function(人为选择而非机器学习而来),将原始空间的任意两点映射为这两点在目标表示空间中的距离。
决策树:针对一个一个特征进行划分处理,更加接近人的思维按时,可以产生可视化的分类规则,产生的模型具有可解释性。
1. 决策树的学习:自顶而下递归,以信息熵为度量构造一颗熵值下降最快的树,到叶子节点处熵值为 0。 2. 随机森林:利用样本的随机和特征的随机,建立多棵决策树,这些树形成随机森林,通过投票表决结果,决定数据属于哪一类。 3. 梯度提升机:较少的决策树就能够获得较高的准确率,在最优化目标函数的过程中导出的。[与随机森林的对比](https://yq.aliyun.com/articles/216164)。深度卷积神经网络算法,应用在 CV、NLP 等感知任务的领域。

- 过拟合:[理解]机器学习模型在新数据上的性能比在训练数据上要差。比如,训练精度 99.9%,但是测试精度只有 60%,说明学习模型出现了过拟合。
- 张量:一种几乎总是存储数值的数据结构(通常存储的类型有:float32、uint8、float64 ,少量情况下的 char 等),是矩阵向任意维度的推广。
- 具有维度/阶的概念,也就是某一张量中轴的个数,称为
ndim。 - 零维张量也叫标量,是仅包含一个数字的张量。
- 一维张量也叫向量,其实就是一个一维数字数组。
- 二维张量也叫矩阵,二维数字数组。
- 具有维度/阶的概念,也就是某一张量中轴的个数,称为