
ARTS 第十二周
每周完成一个ARTS(也就是 Algorithm、Review、Tip、Share 简称ARTS):
- 每周至少做一个 leetcode 的算法题
- 阅读并点评至少一篇英文技术文章
- 学习至少一个技术技巧
- 分享一篇有观点和思考的技术文章。
Algorithm
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
答案中不可以包含重复的四元组。
示例:
给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。
满足要求的四元组集合为:
[
[-1, 0, 0, 1],
[-2, -1, 1, 2],
[-2, 0, 0, 2]
]
思路:
- 先用两个指针 i、j 从左到右遍历。
- 然后再用两个指针 left、right 从两侧向中间靠拢,对比结果。
- 整个数组要先排序。
- 使用 HashSet 去重,需要子 list 进数组前先排序。
1 |
|
Review
本周阅读一篇英文文章:An Introduction to Apache Kafka
解读要点:
如果 n 个app 需要相互交流,传统形式下,可能出现 n×n 种组合形式,在 scalability 系统中,n 可能非常大,过多的组合是无法接受的。所以此时就需要一种类似发布-订阅模式(pub-sub mechanism)来实现上面提过的需求。
历史上来说,一种叫做 JMS(java messaging service)是一种松耦合的消息结构,是早期的 MQ工具,其中的某些特性(比如 producer、consumer、message、queue、topic 等)延续下来,成为后来的MQ工具的核心。
kafka 定义:Apache Kafka is a distributed, partitioned, replicated commit log service.
- 关键词:支持分布式,容错性强,scalable弹性好,发布-订阅模式。
- append-only logs,producer 会将 event 推送到 distributed logs 中,成为一个 topic。
consumer 经过配置后,利用 offset 去消费 topic。此 offset 其实就是 topic 中 record 的编号。
- 让 consumer 决定消费什么,完全避免 producer 侧太过复杂的 routing rules。
commit log:是一种 append-only,时序的 records 序列,与 kafka 的 topics 构成映射,并且分区实现分布式的特性。
记录的是何时发生了何事。log 主体具有独立的时间戳,与物理时钟无关。
分布式系统建议使用异步的方式消费 topic。
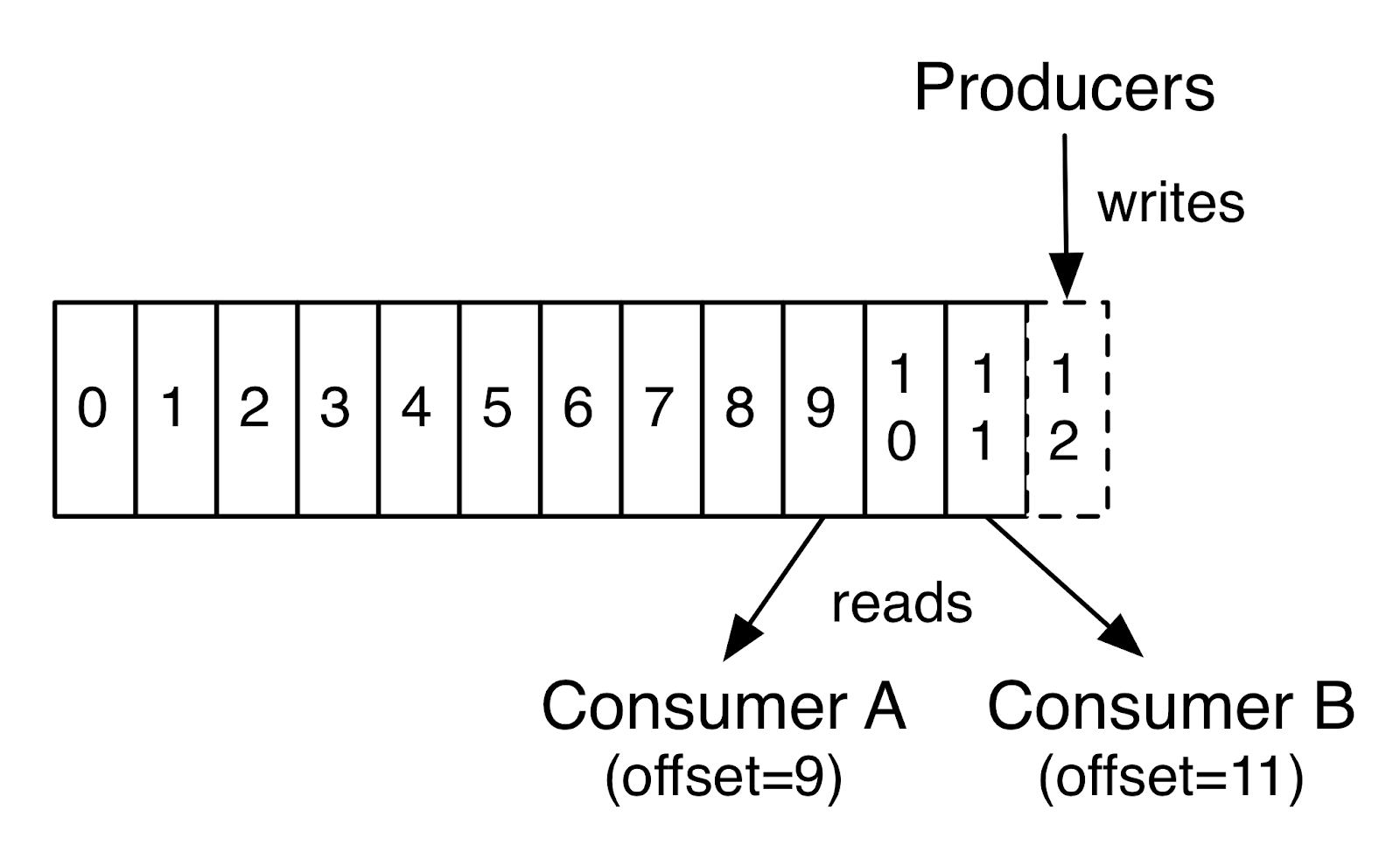
按上图,producers 从右端添加 log,consumer 按照 offset 找到定位,然后从左到右消费 log。
kafka 的有关缺点:
- 不设 index,甚至分区的 topic 也没有 index。
- 可能因为消费侧规则的错误配置,导致某些topic未被消费。
- 当设置 TTL(time-to-live)的消息退出机制(在
.properties文件的log.retention.*中配置),kafka才会删除消息。所以日志内容可能会很大,磁盘 swap 时可能出现延迟。 - kafka 可以通过 kernel IO 进行流处理 message,比 user space 的 IO 要快很多,但在 kernel 中的操作有一些潜在的风险。
Confluent Schema Registry,Confluent 支持的一种 schema 注册机制,是与 kafka配合的一种规范用法。
- producer 注册schema,然后按照此 schema 发布消息,consumer 按照此 schema 解析消息,用以实现 schema 规则的一致性,是 kafka 高级用法的一种。
- 此机制不是 apache 维护的,当心其未来的兼容性。
Aiven 公司也提供了一种开源的 schema 管理工具,Karapace,简单易用。
Tip
分享一波资源网站吧,排名不分先后:
电子书:read678,爱下电子书,鸠摩搜书,苦瓜6 寸pdf
乱炖:爱吃大鸭梨
Share
本周分享的是 zookeeper 的基础知识点,以及 server 和 client 搭建实战,参考本站另一篇文章,
链接如下:zk学习笔记