
Akka 核心知识梳理
本文参考自 segmentfault 中的 JVM 并发框架 Akka 专栏,此专栏质量非常高,推荐!
以下是我对核心知识的梳理:
核心知识点
Actor 模型
是一种比线程还要轻量级的时间处理模型,文中说 1GB 可以容纳百万级别个 Actor,算了一下,一个 Actor 占 1KB 内存?
是一种异步、非阻塞、高性能的事件驱动的编程模型。
- 异步:每一个 Actor 都有一个 MailBox 用来收件,假设存在ActorA、ActorB,A 向 B 的 mailBox 发了条 message,然后 A 就不管了,也不需要等回复;B 对 mailBox 中来自 A 的 message 进行处理后,B 会向 A 的 mailBox 发一条消息,这条消息就相当于 response 了。这么看来,Actor 的 send 和 receive 消息就是异步的了。
- 非阻塞:MailBox 接收消息允许并发,对消息的 response 也是异步进行的,所以非阻塞。
- 高性能:第一:每个 Actor 对自己的 MailBox 中消息的处理是串行的(虽然接收消息允许并发,MailBox 的数据结构见下文),所以没有共享数据的困扰(共享数据可能涉及到锁形式、锁粒度选取等各种问题,初学程序员往往不能很好解决这些问题)。第二:Actor 是非常轻量级的,程序中允许有许多个 Actor,所以我们要做的就是将相应的并发事件尽可能拆分成一个小的事件,再配合 Actor 的异步特性,实现高性能。
是一种并发模型的封装,更高层面的抽象。
可以看一这篇详细理解Actor:Actor解决了什么问题?,精华:
java 中,两个线程调用同一个方法,但被调用的对象并不能保证其封装的数据发生了什么,两个调用的方法指令可以任意方式的交织,无法保证共享变量的一致性。
所以一般的解决办法是给方法加锁,但是加锁代价昂贵而且容易出现死锁。本地加锁已经很慢了,如果是分布式环境,加上分布式锁效率又要低上几个量级。
java 中调用堆栈来进行任务的执行,比如线程将任务委托给后台,并把任务添加到一个内存位置,然后后台起另外一个线程进行任务执行,从该内存位置上选取任务执行。这个过程涉及到两个线程,一个是调用者线程,另一个是执行者线程。那么问题来了,执行者线程完成任务的通知该怎么告知调用者线程呢?如果任务发生了异常,由执行者线程处理异常合理不合理呢?不合理,因为当执行者线程出现异常时,不确定该由谁来重新线程并保存线程之前的状态。而且可能因执行者线程的异常,异常逐级上传时导致调用者线程所共享的任务队列状态全部丢失。
如果想实现高并发且高效性能的系统,线程必须将任务有效率的委托给别的线程执行以至不会阻塞,这种任务委托的并发方式在分布式的环境也适用。所以 java 中的高并发模型需要引入错误处理和失败通知机制。
Actor 模型采用消息机制,发送消息的方式不会将发送消息方的执行线程转换为具体的任务执行线程。Actor可以不断的发送和接收消息但不会阻塞。这种方式与方法调用方式最大的区别就是没有返回值。
ActorSystem
- 对 Actor 进行统一调度,主要做①管理调度、②配置相关参数、③日志
- 管理调度:ActorSystem 做的就是分拆任务,直到一个任务小到可以被完整处理,然后交给 Actor。Actor 就像多叉树一样(也类似文件系统,很容易确认 Actor 具体位置,所以是天生的分布式),有父 Actor,有子 Actor。父 Actor 负责给子级 Actor 分配资源、任务,并管理其生命状态。最下层 Actor,也就是叶子节点的 Actor 就是执行具体逻辑的单元。
- 配置相关参数:根据配置文件的内容,加载相应的环境(比如日志输出级别等),并应用到整个 ActorSystem 中(lee 理解:配置单位是 ActorSystem 级别的)。
- 日志功能:因为 Akka 的高容错性、以及持久化的需求,所以 ActorSystem 拥有完善的日志记录。
- 对 Actor 进行统一调度,主要做①管理调度、②配置相关参数、③日志
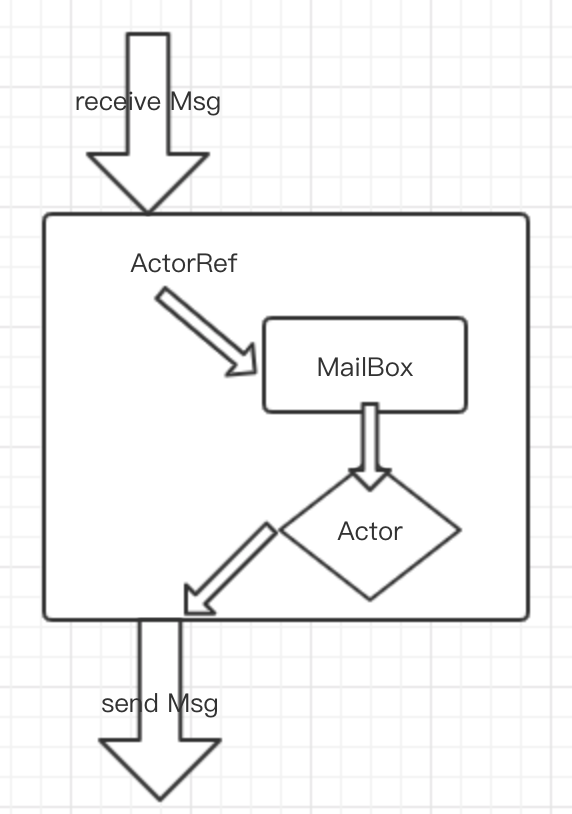
ActorRef,别名:Actor 引用(lee 注:这两个概念并不一样,但在这里本人不做区别,因为没必要)
- 每一个 Actor 都有自己唯一的 ActorRef,ActorRef 可以看做是 Actor 的代理,接收发送消息其实都是由 ActorRef 代劳的。
新建 ActorRef / 拿到已存在 ActorRef 的方式
- 用 ActorSystem.actorOf
- 用 ActorContext.actorOf
- 路径拿到已存在的 ActorRef
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15trait Message{val content: String}
case class Business(content: String) extends Message{}
// 方法一:ActorSystem.actorOf 创建 ActorRef
// 注: 需要提前定义好 BossActor
val actorSystem = ActorSystem("company-system")
val bossActor = actorSystem.actorOf(Props[BossActor],"boss")
bossActor ! Business("Fitness industry has great prospects")
// 方法二:ActorContext.actorOf 创建 ActorRef
// 注: 需要提前定义好 ManagerActor
val managerActors = (1 to 3).map(i => context.actorOf(Props[ManagerActor],s"manager${i}"))
//方法三:由路径取得已存在的 ActorRef,甚至父 Actor:*Actor.actorPath路径:示例
/user/boss,根守护者/,然后是下级 Actor:user,再下级 Actor:boss。- 由路径可以找到具体 Actor 的位置,上面示例的完整位置是:
akka://company-system/user/boss,如果是远程 akka,那么地址就会变成akka.tcp://company-system/user/boss,或者是 akka.udp 开头等。 - 如果使用了第三方插件,远程调用地址会有另外的写法。
- 由路径可以找到具体 Actor 的位置,上面示例的完整位置是:
监管:就是容错,主要对系统环境错误、异常时的错误恢复
监管者:Actor 都是监管者(甚至
/是顶级 Actor 的监管者)主要执行“父监管”的形式
系统创建时会至少启动三个 Actor:
/、/user、/system。user、system 都是顶级 Actor,顶级 Actor 还有:deadLetters、temp、remote- user:用户创建的actor 放在此子树下,比如
ActorSystem.actorOf创建的 - system:系统创建的 actor 放在此子树下,比如日志 actor
- 对除了
ActorInitializationException和ActorKilledException之外的 Exception 无限执行重启。
- 对除了
- deadLetters:死信 actor,发往不存在或不存活的 actor 的信息会被重定向到这里
- temp:短时 actor,比如
ActorRef.ask用到的 - remote:存放一些 actor,这些 actor 的监管者是远程 actorRef
- user:用户创建的actor 放在此子树下,比如
监管策略:恢复下属、重启下属、永久停用下属、升级失败(沿监管树向上传递失败,由此失败自己),比如下面自定义的策略:
1
2
3
4
5
6
7override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume //恢复
case _: NullPointerException => Restart //重启
case _: IllegalArgumentException => Stop //停止
case _: Exception => Escalate //向上级传递
}- 自定义监管策略时,需要重写
supervisorStrategy方法,而且需要指定采用策略应用范围:OneForOneStrategy或AllForOneStrategy,前者策略只会用在发生故障的子 actor 上,后者策略应用到所有的子 actor 上,一般都会用前者。
- 自定义监管策略时,需要重写
Akka 共享内存
- 通过通讯实现共享内存,而不是通过共享内存实现通讯
- java 的共享内存是多个线程经历获取锁、操作内存,释放锁的过程,内存值就是多线程的通讯信息。
- akka 的 actor 机制,就是将操作内存的机制进行了一层封装,操作共享内存的动作变成了消息的接收和发送,actor 利用本身串行处理消息的机制来保证内存的一致性。
- Akka 的这种机制还需要满足:消息的发送必须先于消息的接收。
- 如果消息对象未初始化完整,Actor 收到的消息会不完整,接收者可能接受到不正确的消息,导致发生奇怪的异常。
- 通过通讯实现共享内存,而不是通过共享内存实现通讯
Actor 的 Mailbox
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// Mailbox 的数据结构
private[akka] abstract class Mailbox(val messageQueue: MessageQueue)
extends ForkJoinTask[Unit] with SystemMessageQueue with Runnable {}
// mailbox 内部的 run 方法
override final def run(): Unit = {
try {
if (!isClosed) { //Volatile read, needed here
processAllSystemMessages() //First, deal with any system messages
processMailbox() //Then deal with messages
}
} finally {
setAsIdle() //Volatile write, needed here
dispatcher.registerForExecution(this, false, false)
}
}
// Mailbox.Status ,由 volatie 保证可见性的 int 变量,使用 CAS 方法修改
final def currentStatus: Mailbox.Status = Unsafe.instance.getIntVolatile(this, AbstractMailbox.mailboxStatusOffset)
// processMailbox() 方法
private final def processMailbox(
left: Int = java.lang.Math.max(dispatcher.throughput, 1),
deadlineNs: Long = if (dispatcher.isThroughputDeadlineTimeDefined == true) System.nanoTime + dispatcher.throughputDeadlineTime.toNanos else 0L): Unit =
if (shouldProcessMessage) {
val next = dequeue() //取出下一条消息
if (next ne null) {
if (Mailbox.debug) println(actor.self + " processing message " + next)
actor invoke next
if (Thread.interrupted())
throw new InterruptedException("Interrupted while processing actor messages")
processAllSystemMessages()
if ((left > 1) && ((dispatcher.isThroughputDeadlineTimeDefined == false) || (System.nanoTime - deadlineNs) < 0))
processMailbox(left - 1, deadlineNs) //递归处理下一条消息
}
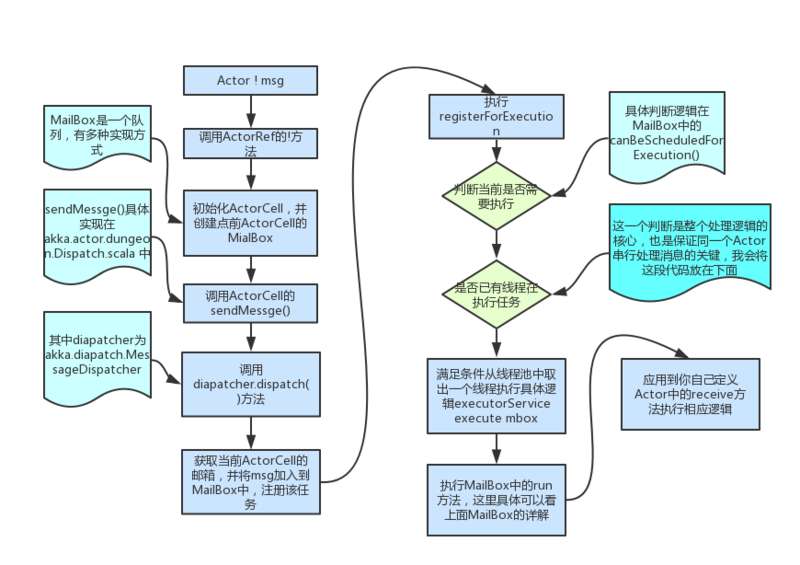
}mailBox 中维护了一个messageQueue 的消息队列,并继承了 ForkJoinTask 任务执行类,以及 Runnable 接口。
消息队列保证了消息执行的异步性
processMailbox 方法采用递归的方式逐条取消息并处理。
再深入理解一下下面这张图:
Scala 中的 Future
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// 1. Future 基础用法
val fut = Future {
Thread.sleep(1000)
1 + 1
}
fut onComplete {
case Success(r) => println(s"the result is ${r}")
case _ => println("some Exception")
}
println("I am working")
Thread.sleep(2000)
//console:
// I am working
// the result is 2
// 2. Future 高级用法:多个 Future 组合
val fut1 = Future {
println("enter task1")
Thread.sleep(2000)
1 + 1
}
val fut2 = Future {
println("enter task2")
Thread.sleep(1000)
2 + 2
}
for {
v1 <- fut1
v2 <- fut2
} yield println(s"the result is ${v1 + v2}")
//console:
//enter task1
//enter task2
//the result is 6Akka persistence.
需要持久化的 Actor 都要继承
PersistentActor并实现三个属性:persistenceId、receiveCommand、receiveRecover。- 唯一 id。
- 正常处理消息逻辑(跟普通 actor 相似):可以在这里实现 persist 方法,做出
saveSnapshot或者别的持久化动作。 - 重启恢复时的执行逻辑:更新状态、或者快照恢复 actor 等动作。
持久化方法:
persist和persistAll,参数都是持久化事件,以及持久化的后续处理逻辑。还有两个关键概念:
Journal,Snapshot,前者是持久化事件,后者是 actor 快照。Akka persistence 使用了CQRS(Command Query Responsibility Segregation)架构设计的理念。核心:
写操作经系统初步处理后生成一个事件 event,会立刻发起 response,但真正执行的写动作是异步的。
事件 event 会先进行持久化,所以一旦执行写动作发生异常时,可以根据 event 进行恢复。
实现的是最终一致性,可能对某些场景不适用。
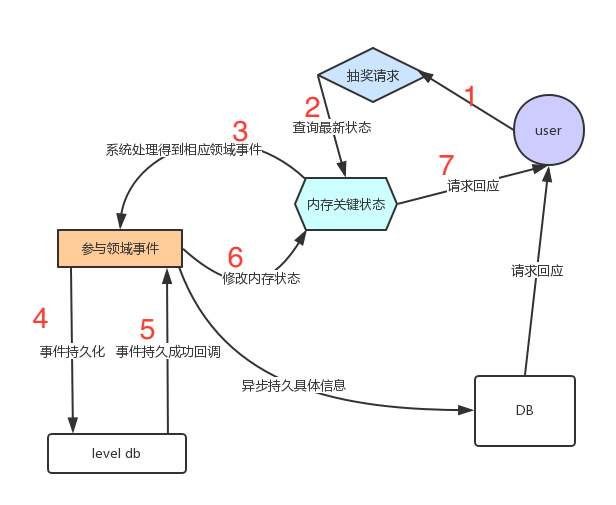
4. 系统在持久化相应的领域事件后和修改内存中的库存(这个处理非常迅速)后便可马上向用户做出反应,真正的具体信息持久可以异步进行。
Akka Remote
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43// 通信双方都要进行配置(remote、client):
akka {
actor {
provider = "akka.remote.RemoteActorRefProvider"
}
remote {
enabled-transports = ["akka.remote.netty.tcp"]
netty.tcp {
hostname = $localIp //比如127.0.0.1
port = $port //比如2552
}
log-sent-messages = on
log-received-messages = on
}
}
// 远程服务器上创建 RemoteActor,接收 msg,并打印 response 到 console
class RemoteActor extends Actor {
def receive = {
case msg: String =>
println(s"RemoteActor received message '$msg'")
sender ! "Hello from the RemoteActor"
}
}
val system = ActorSystem("RemoteDemoSystem")
val remoteActor = system.actorOf(Props[RemoteActor], name = "RemoteActor")
// 本地 client 端:
// 配置文件中 remote.actor.name.test值为:akka.tcp://RemoteDemoSystem@127.0.0.1:4444/user/RemoteActor
case object Init
case object SendNoReturn
class LocalActor extends Actor{
val path = ConfigFactory.defaultApplication().getString("remote.actor.name.test")
implicit val timeout = Timeout(4.seconds)
val remoteActor = context.actorSelection(path) // 获取 remote actor
def receive: Receive = {
case Init => "init local actor"
case SendNoReturn => remoteActor ! "hello remote actor"
}
}先启动 remoteActor,再启动 localActor:
1
2
3
4
5
6
7
8
9
10
11
12object RemoteDemo extends App {
val system = ActorSystem("RemoteDemoSystem")
val remoteActor = system.actorOf(Props[RemoteActor], name = "RemoteActor")
remoteActor ! "The RemoteActor is alive"
}
object LocalDemo extends App {
implicit val system = ActorSystem("LocalDemoSystem")
val localActor = system.actorOf(Props[LocalActor], name = "LocalActor")
localActor ! Init
localActor ! SendNoReturn
}此时 RemoteActor 的 console 会打印两条消息:
1
2RemoteActor received message 'The RemoteActor is alive'
RemoteActor received message 'hello remote actor'注:此 RemoteActor 收到消息并进行回复,但 localActor 并未接收回复消息,如果需要接收回复,可以在 localActor 创建一个消息
SendHasReturn:1
2
3
4
5
6
7case object SendHasReturn
def receive: Receive = {
case SendHasReturn =>
for {
r <- remoteActor.ask("hello remote actor")
} yield r
}重新运行 localActor,就能在 local 处收到回复:
Hello from the RemoteActorAkka Serialization
Akka 原生序列化(即采用 java 中的 java.io.Serializable):
1
2
3
4
5
6
7
8
9
10// 修改 9 Akka Remote 中 localActor 的 Receive 方法,
// joinEvt 会被序列化(Akka 底层做的),传输到 remoteActor 上
case object SendSerialization
case class JoinEvt(id: Long,name: String)
def receive: Receive = {
case SendSerialization =>
for {
r <- remoteActor.ask(JoinEvt(1L,"godpan"))
} yield println(r)
}第三方序列化工具——kryo:
使用 Kryo 时,先导入 Kryo 的依赖,然后只需要在
application.conf中配置即可完成:1
2
3
4
5
6
7
8
9
10actor {
provider = "akka.remote.RemoteActorRefProvider"
serializers {
kryo = "com.twitter.chill.akka.AkkaSerializer" // 地址
}
serialization-bindings {
"java.io.Serializable" = none
"scala.Product" = kryo //使用 kryo 作为序列化工具
}
}
Akka cluster
就是一些相同的ActorSystem的组合,它们具有着相同的功能。待执行的任务可以随机的分配到目前可用的 ActorSystem 上。基于 gossip 协议,将请求转发给运行正常的服务器去。
Seed Node,用于可以自动接收新加入集群的节点的信息,并与之通信。
1
2
3
4
5// Seed Node 的配置文件,第一个会在集群启动时初始化,后面的用到时初始化
// 配在这里的机器,相当于加入了 akka 的集群中
akka.cluster.seed-nodes = [
"akka.tcp://ClusterSystem@host1:2552",
"akka.tcp://ClusterSystem@host2:2552"]cluster events。节点对于集群可能存在六种动作(正在加入,加入,正在离开、离开、可触达、不可触达)。
集群中各节点的功能允许有所不同,即拥有不同的 Roles,比如 request、compute、store 等等。
cluster client,可以将集群中某一个节点作为集群客户端,作为外部通信的接入口,此节点按以下配置:
1 |
|