
【题外话】机器学习论文怎么写:
很大一部分论文描述或研究了新的机器学习方法或理论。这类论文的例子可能包括: 一篇提出新的学习算法的论文; 一篇描述困难应用的解决方案的论文; 或者一篇证明某种学习方法的错误的界限的论文。这些论文有望作出重要的(i)算法,(ii)应用,或(iii)理论贡献。NIPS 寻求发表在世界上有很高影响力的论文——不仅在我们的研究社区,而且在其他领域。因此,在适当的情况下,将根据以下五个标准对文件进行评价:
- 算法的新颖性。例如,一篇论文给出了一个算法的优雅的新推导; 或者一篇论文提出了一个解决现有问题的新方法。
- 应用/问题的新颖性。例如,一篇论文提出了一个重要的应用,迄今为止很少在 NIPS 研究。或者,引入一个新的机器学习问题(过去的一些例子包括独立分量分析和结构预测) ,并提出一个算法。
- 应用的难度。例如,将机器学习应用于一个困难的、重要的、“真实”的应用程序,它考虑到让一个非琐碎的系统工作的全部复杂性。
- 结果的质量。该算法是否经过严格论证,能够对所考虑的任务给出良好的经验性表现(在这里,“真实”数据或“真实”实验可能比“人工”或“玩具”实验更有效) ,或者理论结果是否强大和有趣等等。
- 洞察力传达。论文是否传达了对算法性质的洞察力; 实际应用或问题的性质; 学到的一般经验教训; 以及/或其他人今后工作可能使用的理论或数学工具。
论文的类型:
- 为该模型提出了一种新的自然学习模型和算法(例如: 贝叶斯学习、统计学习、 PAC 学习、在线学习、 MDP 学习、 Boosting)。
- 在一些标准设置中提出了一种改进的算法并进行了分析。
- 证明一些人一直在尝试的学习任务是困难的或不可能的。
- “其他”。学习定理的元定理等。技术上的困难或新奇不是目标。影响学习的过程和实践是目标。实验结果是好的,但一般来说是不必要的。
基于深度学习的MOOC作弊行为检测研究
万子云,陈世伟,秦斌,聂伟,徐明.基于深度学习的MOOC作弊行为检测研究[J].信息安全学报,2021,6(01):32-39.
为了提高教育平台的学分认可度,需要做防作弊的研究。
被动防护:技术手段禁止学习者在在线学习过程做一些违规操作。
- 早期技术:例如,采用操作系统内核的API调用技术、系统消息拦截技术、回调技术、钩子技术、注册表访问技术等手段对一些违规操作实施禁用或者屏蔽,从而达到禁止学生进行页面切换、答案复制及互助抄袭的目的。
知识:
正常的学习者会先观看学习视频,再做练习,最后提交答案,异常的学习者可能会直接做练习或者集中在某一个时间段进行刷课等。
异常行为检测问题广泛存在于各个领域,例如网络入侵检测[5,6]、信用卡欺诈检测[7]、故障检测[8]、居民用电检测[9]。根据已有的文献研究,异常行为检测算法可以分为基于人工提取特征的传统机器学习算法和基于自动化提取特征的深度学习算法[10],但是传统机器学习算法过度依赖于人工特征提取,且常常由于特征提取不完整,导致模型性能不佳等问题。因此,许多学者尝试使用基于深度学习的方法进行异常行为检测。
研究现状——适用于特定作弊形式:
- 常永虎等人基于考生在网络考试中的行为数据,提出了一种基于互相抄袭的作弊检测算法,该算法通过计算考生在答题的时间和答案上的相似度来判断作弊的可能性。
- Ruiperez-Valiente J A等人开发了一种算法来识别使用CAMEO(使用多个账号复制答案)方法进行作弊的学习者,该算法通过比较学习者、问题和提交特征对CAMEO的影响,建立了一个不依赖IP的随机森林分类器,以识别CAMEO学习者。
- Sangalli V A等人[3]针对学习者互相分享答案以及使用虚假账号获取正确答案这两种作弊手段,设计了一些指标来得到相应的特征,再利用K-means聚类算法对其进行聚类来识别使用这两种作弊手段的学习者。
研究现状——通用场景
- 卷积神经网络(Convolutional Neural Networks,CNN)[11]与循环神经网络(Recurrent Neural Networks,RNN)[12]是比较常见的深度学习网络模型,CNN的优势在于能够在空间维度上提取局部特征,RNN的优势在于能够在时间维度上提取时序特征。对于复杂的MOOC学习者的学习行为数据,一般是具有序列性质的,因此,在挖掘学习行为特征时,需要考虑其空间上的联系,也需要考虑其时间维度上的关联信息。
- 本文尝试将深度学习模型应用于MOOC作弊行为检测中,结合CNN和RNN网络模型来对学习者的学习行为序列进行建模,但是,普通的RNN一方面存在着梯度消失的问题,另一方面只能学习单个方向的时序特征,为了解决这些问题,本文将RNN网络替换成其变种网络—双向门控循环单元(Bidirectional Gated Recurrent Unit,Bi GRU)[13],采用CNN-Bi GRU联合网络提取学习行为序列的空间及时序特征。(1)针对之前的MOOC作弊行为检测方法存在的应用场景单一化,过度依赖人工提取特征,检测效果不稳定等问题,本文提出了一种基于CNN-Bi GRU-Attention联合网络的MOOC作弊行为检测模型,该模型融合了CNN、Bi GRU、Attention三层网络结构,实现了自动化特征提取,可以适用于多种作弊形式的检测,性能较好。
样本选取:
在进行MOOC作弊行为检测研究时,相对于正常样本,作弊样本往往是少之又少。基于此,本文采用序列截断扩增、平移扩增这两种数据扩增方法来增加作弊行为序列的样本量。截断扩增,具体而言就是对长度过长的作弊行为序列进行截断,将截断后的序列打上作弊的标签,从而增加作弊标签的样本量。而平移扩增是指通过时间滑窗的方式,以24 h的固定窗口前后滑动,获取一段新的作弊行为序列。
行业成熟应用
有效防止学员通过挂机的方式进行学时作弊:**防切屏模式 **/ 规定时间内的离开提醒(播放视频时隔一段时间检测鼠标任务)
Identifying Cheating Users in Online Courses
Sangalli, V. A., Martinez-Munoz, G., & Canabate, E. P. (2020). Identifying Cheating Users in Online Courses. 2020 IEEE Global Engineering Education Conference (EDUCON). doi:10.1109/educon45650.2020.9125252
学生类型:通读所有材料和练习的学生,以复习内容为主的学生,以及少数以做练习为主的学生。
A. Co-occurrence in exercise answers
事件的同时发生是一个用户与另一个用户的关联程度的指标;在相同的时间做相同练习的帐户们将被认为是可疑的。
- 为了计算可疑的用户对,首先计算每个可能的用户对在短时间内做相同的练习的次数。
- 然后,为了进行后续分析,我们将在给定的时间范围内回答了至少一定数量的练习的学生配对。设置最小练习数是为了排除在同一时间窗口中偶然回答相同练习的用户。我们考虑的时间框架为1分钟,2分钟,5分钟和10分钟,期间发生最少10~20 个相同的练习
B. Interaction types
- △t 基本都是负数
- 巧合出现的几乎都是XC和CC, 这些模式似乎是使用收获帐户(CAMEOtechnique)的真实用户的清晰暗示。其中分享 IP 的比例高是 CAMEO 的典型特征,比例低则不一定。
- 很少有第一答案正确和第二错误(CX)的情况。 缺少这种模式和答案的同时出现似乎是两个真实用户之间进行协作的明确指标
C. Amount of pairs of users and shared exercises
- 许多用户都有不止一对可疑账户。一个用户可能有几个收获帐户,或者一组用户相互协作。
- 多组时间窗口:1、2、5、10 分钟,完成 10 个、20 个练习的 unique user 的柱状图分布情况。全文以 2 分钟至少 10 个练习进行实验!
计算过程step
- 确定用户偏向。即 UB(u1, u2),UB为正表示u1 做题发生在 u2 之后。
- 计算最终得分差。
- 如果一对用户在一个时间窗口内解决相同的练习并具有较高的最终分数差异,则表明这对用户可能由区域帐户和虚假帐户组成,因为存在一个不关心最终分数的帐户。
- 相反,如果他们的最终成绩差异很小,则可能表明两个合作的学生,因为他们都试图通过该课程。
- 材料和练习的比例 MIR。
- 共享 IP 的比例。
KMeans 做法:
为了自动识别收割者和合作者,我们对先前定义的变量进行了K-均值分析。 具体来说,对于每对分别应用1分钟,2分钟,5分钟和10分钟的时间框架以及最少10和20次练习的帐户,我们计算了指标:用户偏见,得分差异,最小MIR和共享IP地址的百分比。 由于用户偏见和得分差异根据用户排列的顺序而具有不同的符号,因此我们选择对用户输入的顺序进行排序,以使用户偏见为正,并保留该顺序以计算其他指标。 这样做是为了避免仅由用户输入的顺序引起的歧义。 此外,还添加了CC和XC案例的百分比作为属性。 在处理数据集之前,通过去除均值和按比例缩放到单位方差来对功能进行标准化。 K-means是使用k = 2执行的,结果被用于将成对的帐户标记为a harvester pair和a collaborator pair
Detecting and preventing“multiple-account”cheating inmassive open online courses
Northcutt, C. G., Ho, A. D., & Chuang, I. L. (2016). Detecting and preventing “multiple-account” cheating in massive open online courses. Computers & Education, 100, 71–80. doi:10.1016/j.compedu.2016.04.008
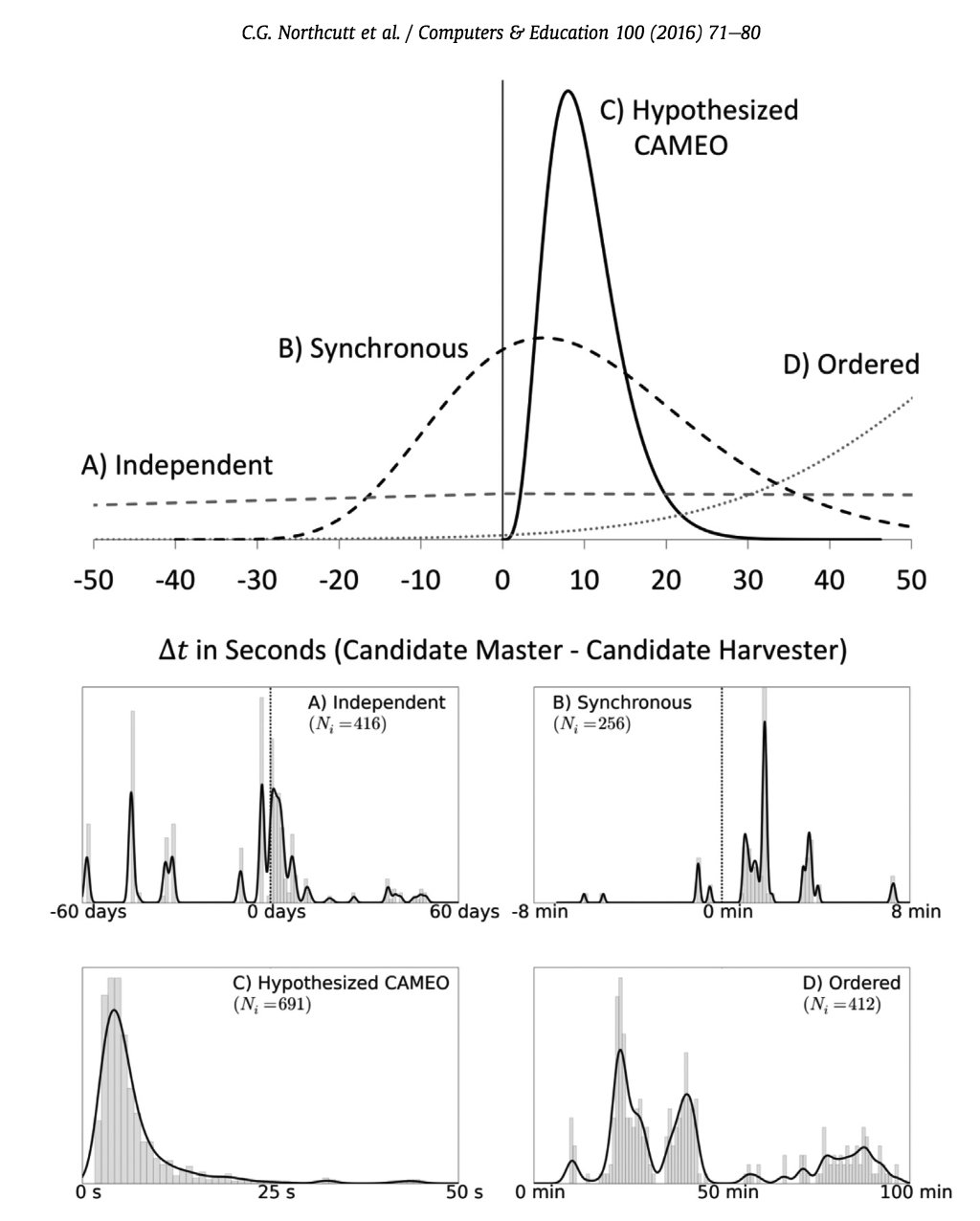
分布 B 代表两个合作者,有时一个人的答案先于另一个人,有时会反过来,但时间会非常接近。
分布C 是 CAMEO 行为的典型。
分布 D 只是一种有序的巧合,可以通过注册时间或者时间偏好来过滤掉。
The Detection of Cheating on E-Exams in Higher Education—The Performance of Several Old and Some New Indicators
AUTHOR=Ranger Jochen, Schmidt Nico, Wolgast Anett TITLE=The Detection of Cheating on E-Exams in Higher Education—The Performance of Several Old and Some New Indicators JOURNAL=Frontiers in Psychology VOLUME=11 YEAR=2020 PAGES=2390 URL=https://www.frontiersin.org/article/10.3389/fpsyg.2020.568825 DOI=10.3389/fpsyg.2020.568825 ISSN=1664-1078
五种不同类型的指标。
- 我们考虑的person-fit指标,评估规律的考生的反应模式。这些指标是 U1统计量(van der Flier,1977)、 U3统计量(van der Flier,1982)、 CS 统计量(Sato,1975)和 HT 统计量(Sijtsma,1986)。
- 当一个考生的回答和所有其他回答之间的平均协方差为零时,HT 统计值为零,其最大值为1,越小越异常。
- 基于响应时间的指标。这些指标是 KL 统计量(Man 等,2018) ,一个类似于 Marianti 等人(2014)和 Sinharay (2018)提出的 Z2统计量,和一个新的指标ー KT 统计量ー来评估一个考生的反应时间模式的 Guttman 同质性。
- KL:基于考生在单题上花费的总测试时间的比例,评估了一个考生的反应时间剖面与样本中的平均反应时间剖面的一致性,越大说明欺骗。
- KT 统计评估一个考生的个人答复时间是否与样本中的典型答复时间顺序相同。
- 基于响应修订数量和相应响应时间的指标(Qualls,2005; Bishop 和 Egan,2017)。其中两个指标(N1、 N2)与答复修订次数有关,两个指标(NC1、 NC2)与修订次数有关,三个指标(T1、 T2、 T3)与修订次数有关。
- N1和 NC1统计量化了考生在考试期间改变答案的频率。它们是基于最后一次尝试的反应。N1 是考生修改次数,这个修改是否由不正确答案改为正确答案[ NC1(g) = 1]。
- N2 和 NC2 量化了中途修正的情况。
- T1、 T2和 T3统计值反映了回答问题所需的时间。
- 基于答复和答复时间之间关系的指标。这个指标(CD)是库克的距离总测试时间的回归总得分的反应。
- CD 统计评估考生的数据模式是否与样本中测试成绩和总测试时间之间的一般关系一致。
- 基于不同考生反应模式相似性的两个指标(Maynes,2017; zoploglu,2017)。第一个指标(PT)是根据相同答复的数量确定的,第二个指标(PI)是根据相同的错误答复的数量确定的; 关于早先对教育测试领域某些指标的表现进行的研究,见卡拉巴索(2003年)、 Tendeiro 和 Meijer (2014年)、 Kim 等人(2017年)、 Sinharay (2017年)和 Man 等人(2018年)。
- PT 和 PI 统计评估不同考生的反应模式的相似程度。对于 PT 统计信息,可以将每个响应模式与样本中最相似的响应模式匹配。这是具有最多相同数量的响应模式。PT 统计量是反应模式中相同反应的相对频率及其匹配。PI 统计量与 PT 统计量相似,只有一个例外。为了确定最相似的响应模式,只考虑不正确的响应。PI 统计量是相同的不正确答案在回答模式及其匹配中的相对频率。
Towards a General Purpose Anomaly Detection Method toIdentify Cheaters in Massive Open Online Courses
Alexandron G , JA Ruipérez-Valiente, Pritchard D E . Towards a General Purpose Anomaly Detection Method to Identify Cheaters in Massive Open Online Courses. 2020.
- 我们证明了一种基于异常检测的通用检测方法,在一种作弊类型上进行训练,可以泛化地检测使用其他方法的作弊者。
- 其次,我们提出了一个新的基于时间的个体异常行为统计。
主要贡献:
- 使用了更通用的参数:GE、GE-time、video-watch-time、Fraction of videos watched 这些。
一种干部在线作弊学习行为分析与预测策略
陈乾国. 一种干部在线作弊学习行为分析与预测策略[J]. 计算机工程, 2017, 43(009):17-22,28.
作弊检测规则:
- 同一时间学习多门课程,Cnum≥2,则判定该学员存在作弊学习行为。而此种情况又具体分为下面 2 种类型:
- 同一时间学习完成,则判定学员存在作弊学习。
- 同一时间开始学习多门课程,即判定为作弊学习行为。
- 学员学习视频课程所用时间小于课程总时长的 80% ,则判定学员存在作弊学习行为。
- 学员学习视频课程结束时间小于课程学习开始时间,这明显违反学习规则,判定为作弊学习 行为。
- 学员在1d之内所学课程时长总和大于 24 h,即判定为存在作弊学习行为。
首先对数据集中学习记录的每个特征进行编码,根据编码对学习记录进行识别与检测分析。 然后,利用第 1 节中的作弊检测规则及步骤,分析 干部学员的学习特点,对每条学习记录进行检测分析,发现存在作弊行为的学习记录(lee:相当于打标签了)。这种模式对数据量相对较少的数据集处理起来方便准确,但一旦数据量过大,此种模式的检测效率将大大降低。下面将以本节的检测结果集作为基准进行数据挖掘,分析和预测学员学习行为。
模型:libSVM
一种在线学习平台检测刷课作弊的技术
王晖, 宋学庆. 一种在线学习平台检测刷课作弊的技术:.
定时心跳检测:检测用户播放时长以及视频间隔播放的时间点,数据库中两次相邻插入播放记录的时间差值,若小于本地提交播放时间,说明存在刷课行为。
刷课、代考、异常操作学员账号。
同学,我们已经发现您具有相应的网络知识,了解浏览器的调试模式,这挺好的,以下是要对您说的一些警告信息。警告:请不要以任何取巧方式进行作弊刷课或帮助其他人刷课,系统已对所有课时的真实性进行统计计算评估,收集数据包括不限于(浏览器头,版本,播放器记录,登录时长,cookie,referer,ip追踪,终端平台,是否符是您的账号,登录过多少个账号,历史登录记录.. 等各种操作数据及ajax随机埋点),一经发现作弊轻则取消学时,重则取消成绩。
一个是通过行为的判定,比如很机械化的规律操作(这个几率很低)
第二个是通过IP判断,一般来说刷课平台用家庭IP就很安全,但是难免同学要登录签到上直播课,可能导致ip全国飞来飞去,增加了检测的几率。所以能提供签到+直播的平台可以完美解决这个问题。
第三是小白喜欢用秒刷,高倍数去刷完课,但是官方并不提供相应倍数,就时长与学习记录不匹配,可以抓。
- 通过 JavaScript 脚本把手动点击模拟为脚本自动点击下一步等一系列操作
他为啥能判断你作弊?后台大数据..?”别太高估了这群可能是外包的开发人员”
在学习通的服务器端检测机制:
- 当你第一次请求播放 API 的时候,他会记录你请求的时间戳,然后每隔 60 秒检测一次心跳包。
- 如果你频繁的请求新视频,不论你是加速看的还是直接拖 Safari 进度条,但是你几秒就看完了一节他好几分钟的课的事实,已经明明白白的摆在他服务器的请求数据里面的,然后你也就明明白白的了。
EduSoho学习数据全站升级:学员多开、挂机、刷学时?这个功能帮你全部搞定
“课程学习时长”、“用户学习时长”,”累加学习时长”,”去重学习时长”.
- 在某些网校中,学员为了冲击排行、获取奖励,很可能会使用多个浏览器或多个终端,同时打开不同的学习任务进行刷课。
- 以视频、音频、图文等课程类型为主的网校可以选择“后踢前”策略,方便用户进行终端切换。
- 以作业、考试、直播等课程类型为主的网校则可以选择“前踢后”策略,避免造成学习中断。
- 为了刷满学时,完成规定任务,学员还可能将课程后台挂机,或是在上课的同时切换窗口发邮件、聊天、看视频。
- 网校还可以通过学习行为的差别,对学员的“有效学习时长”进行自由定义。比如以视频的实际播放时长作为统计维度,就可以更有效的防止学员挂机作弊哦
《教育审计分析模型与案例》期刊
主要审计分析模型:
- 学前教育发展总体评价分 析模型。多部门数据关联分析,并按城乡、区际、幼儿园 性质(公办园、民办园)分组,分析了 城乡之间、区域之间、不同性质幼儿 园之间的收费、生均收支、师资力量 等,对南京市学前教育均等化现状进 行总体评价。
- 幼儿园规划制定与落实情 况分析模型。审计不同区域幼儿园规划数 与适龄儿童数据是否匹配,判断幼儿 园规划是否能满足区域需求,审计不 同区域幼儿园规划是否按照进度落 实,将规划与需求严重不匹配、规划 落实严重滞后的区域作为延伸审计 重点。
- 幼儿园教师编制落实情况 分析模型。判断不同区域幼儿园教师编制是否 落实到位,将幼儿园教师严重缺编的 区域作为延伸审计重点。
- 不 同 性 质 幼 儿 园 家 长 、教 师满意度分析模型。并按区域、幼儿园性质进 行分组,分析不同性质、不同区域、不 同财政投入情况下,家长、教师对幼 儿园的满意度。
《基于改进时间卷积网络的日志序列异常检测_杨瑞朋》
检验模型:embedding 层、改进的 TCN 层、自适应平均池化层。
- embedding 层。日志模板序号映射成词向量。
- 改进 TCN。
- 输入第一个一维空洞卷积层,并进行归 一化。需要指明的参数包括日志模板词嵌入的维 度、日志模板词典的大小、卷积核尺寸、步长、padding 大小及是否加入空洞。
- 根据第一个卷积层的输出与 padding 的 大小,对卷积后的张量进行切片来实现因果卷积。
- 因果卷积:利用卷积,从后往前数长度 h 个日志记录,来预测下一个日志记录。特点是该卷积仅依赖于 1,2~h 的输入,而不会依赖 h+1 及以后的输入。
- 添加 PReLU 激活函数。
- dropout
- 堆叠相同结构的第 2 个卷积块,构成一个残差块。
- 自适应平均池化层。